This series intends to explain the concept of GAN Inversion [1], which aims to provide an intuitive understanding of the latent space by inverting an image into the latent space to obtain its latent code.
The series is structured into the following four parts:
- Part I — Introduction to GAN Inversion and its approaches.
- Part II, III & IV — GAN Inversion extensions, applications, and future work.

In Part I, we briefly introduced the concept of GANs and their latent spaces, in addition to introducing the concept of GAN Inversion [1] and its approaches and showed a brief comparison with VAE-GANs.
In Part II, we discussed the characteristics of GAN inversion as well as latent space navigation using the technique.
In Part III, we discussed on some recent extensions to GAN inversion approaches such as In-domain GAN inversion, Force-in-domain and mGANprior.
In this post, which is the final part of a four-part series on GAN Inversion, we’ll discuss on applications and future work.
Please note that we are using the following format variable_subscript for subscripts due to the lack of support for it on medium currently.
1. Applications of GAN inversion
Recent approaches have explored various GAN inversion applications, including image manipulation, restoration, interpolation, style transfer, compressive sensing, and interactive generation. Some researchers looked into the application of GAN inversion for dissecting GANs to understand their internal representations as well as for understanding what GANs do not learn.
1.1 Image interpolation
Image interpolation refers to the process of morphing between two images by interpolating between their corresponding latent vectors in the latent space, usually expecting to achieve a smooth transition between these images. The basic strategy is to perform linear interpolation in the latent space to achieve this, and can be formulated as follows:

where the step factor, λ, is defined as:

z_1 and z_2 represent the corresponding latent vectors of two images, and z represents the latent vector for the interpolated image.
1.2 Image manipulation
With the knowledge that GANs encode rich semantic information in their latent spaces, image manipulation transforms the image’s latent code into specific semantic directions. The basic approach is to perform a linear transformation in the latent space, which can be defined as follows:


where z’ and x’ refer to the manipulated latent code and image, α refers to the step factor, and n refers to a specific semantic direction in the latent space.
1.3 Semantic diffusion
This task aims to diffuse a specific part of a target image into a context image, expecting the output to retain the characteristics of the target image (e.g., face identity) while conforming to the context image. Zhu et al. [4] and Leng et al. [2] investigated the model performance for this application. Fig. 1 and Fig. 2 show their respective results.


1.4 GAN dissection
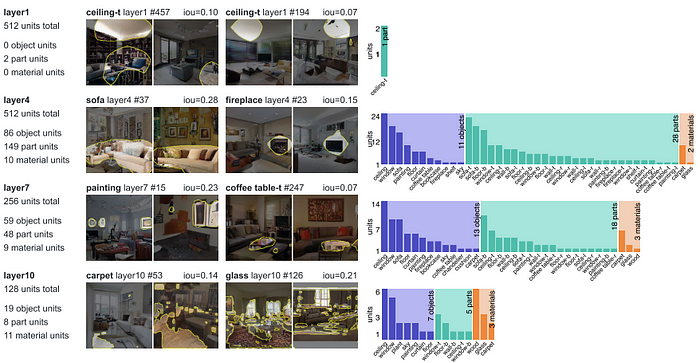
While there has been significant progress in GAN training in the past few years to generate realistic images, there hasn’t been much research on understanding what the GAN learns internally and how the architectural choices could affect the learning. Bau et al. [6] aims to dissect GANs to visualize and understand the encoded internal representations at the unit, object, and scene levels.
The idea is to see whether a particular class c is present in the image.
They suggest that the feature maps r extracted from layers of GAN generators encode some information about the existence of a class c at particular locations in an image, such that for r = h(z) and x = f(r) = f(h(z)) = G(z).
They propose this as a two-step approach:
- GAN dissection: This suggests that for each object class c, the aim is to identify whether the uᵗʰ unit of feature map r_u,P extracted at a particular layer encodes some internal representation of the class at location P. This is done by upsampling the feature map to the image size and thresholding to mask out the non-relevant pixels. It then performs segmentation for class c on the image generated by the generator and performs an IOU check to measure the agreement between the segmented image and the thresholded feature maps.

- GAN intervention: It is important to note that all units highly correlated to an object class are not necessarily responsible for rendering the object into the image. Hence, it is essential to find the set of units that cause an object to occur in the image. They decompose feature maps into unforced and causal (causing object rendering) units and force insertion and ablation of these units to identify their effect. They also incorporate a learnable continuous per-channel factor that implies the effect each unit of feature map has on the rendering.

They also found that dissecting later layers of the generator covered more low-level objects with intricate details like edges and contours, while earlier layers covered broader objects such as a ceiling. Fig. 18 illustrates these findings.
1.5 Interactive generation
Interactive generation refers to generation/modifications to images from user interaction, wherein the user can fill regions to add/remove objects in an image. One interesting application of this is GANPaint by [3]. Their demo can be found here: GAN Paint .
1.6 Seeing what a GAN does not learn
Mode dropping, referring to GANs entirely omitting certain portions of the target distribution, is a challenge in GAN training not explored much. Fig. 6 illustrates the results from image reconstruction using the Progressive GAN church model. As it can be seen, the model drops people or fences during the reconstruction.

Some previous approaches investigated this by measuring the distance between real and generated distributions. Bau et al. [7] proposed an approach to gain a semantically meaningful understanding of what GANs cannot generate, both at the distribution and instance levels. They do this as a two-step approach:
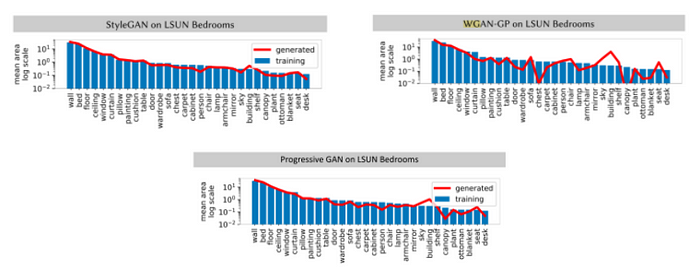
Generated Image Segmentation Statistics: Firstly, they obtain the mean and covariance statistics for different object classes by performing pixel-level segmentation on a set of real and generated images and identifying the total area in pixels covered by each object. If certain object class statistics for generated images depart from real images, it would be something to examine further.
Based on our understanding, objects that occur more frequently in the training set and cover wider pixel areas of the images seem less likely to be omitted by the GAN. While for objects that don’t occur as frequently in the training set, the generator can get away with not generating them at all as the discriminator does not take that as an important feature to classify an image as real/fake.
This approach provides information about classes that GANs omit at a distribution level but does not provide an insight into when a GAN fails to generate an object in a specific image.
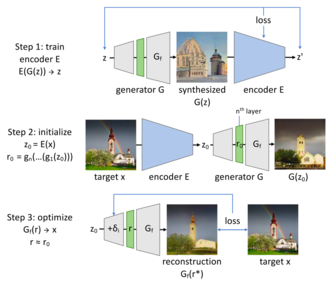
Layer Inversion: This is where GAN inversion comes in. The most basic idea would be to perform GAN inversion to reconstruct an image as close to the real image as possible. However, due to the large size of GANs recently, full GAN inversion is not always practical. Hence, they perform layer inversion instead. To do this, they decompose the generator into layers, such that,
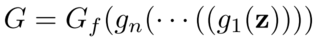
In this case, the initial layers of the generator are described as g_1,…,g_n, while the later layers form G_f. It can hence be concluded that any image that can be generated by G can be generated by G_f. They define r* as G(z) = G_f (r*). Hence, they perform inversion at the layer-level. To get a good initialization for r*, they require a good initialization for z, which is done using the layer-based approach by training an encoder E. z is then passed through g_1,…,g_n to obtain a good initialization for r*, r* is then further optimized to reduce the image reconstruction loss. In order to avoid local minima during optimization, small learnable perturbations (delta) are also added at each layer until the generator’s nth layer, g_n, to obtain better reconstructions.
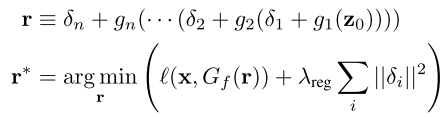
In the loss function, l represents the combination of pixel-level loss and perceptual loss. The loss function also incorporates the perturbations by incorporating a regularization factor, λ_reg.
This proposed architecture is illustrated in Fig 31.
The results on LSUN outdoor church dataset and unrelated (non-church) images can be seen in Fig. 9. It can be seen that the generated images tend to miss particular objects such as humans, furniture, signboard, etc.

It is quite interesting that we rarely see such images being reported by researches, possibly due to this aspect of generated images not being investigated much. Hence, this study by Bau et al. [7] gives great insight into what GANs tend to miss out on.
2. Further improvements
Evaluation metrics
Most current evaluation metrics are concentrated on photo-realism generation quality and comparing training and generated distribution. While some approaches aim to evaluate the generated images by passing them through a classification [7] or segmentation [8] model trained on real images, there is a lack of metrics to directly assess the quality of the inverted latent code and directions of predicted and expected results.
Precise Control
Image manipulation by navigating through the GAN’s latent space using GAN inverted code has been quite successful. However, it is vital to have fine-grained control over attributes manipulated during latent space navigation, for which current approaches are not suitable. For example, it is possible to find latent space directions for GAN models to change pose, however, changing the pose precisely by 1ᵒ is a task that requires more work. Hence, more research is needed to obtain disentangled latent spaces and identifying interpretable directions.
Domain generalization
While many researches have proven effective cross-domain applications including [2], there is still scope for improvement in developing unified models to support multiple applications.
3. Summary
This series on GAN Inversion aimed at summarizing the key technical details of GAN Inversion and its approaches. Additionally, this series also discusses about the extensions and applications of GAN Inversion in recent research. Furthermore, through this series, we also aimed to explore the mechanism of latent space navigation in GAN Inversion.
While we covered the main idea behind GAN inversion as well as some of its applications and extensions in this series, there has been much research in the area recently. Please refer to the survey paper [1] on GAN inversion on which this post is based and [9] which provides a great compilation of GAN inversion resources.
References
[2] Leng, G., Zhu, Y., & Xu, Z.J. (2021). Force-in-domain GAN inversion. ArXiv, abs/2107.06050.
[9] GitHub — weihaox/awesome-gan-inversion: A collection of resources on GAN inversion.
Written by: Sanjana Jain, AI Researcher, and Sertis Vision Lab Team
Originally published at https://www.sertiscorp.com/
