This series intends to explain the concept of GAN Inversion [1], which aims to provide an intuitive understanding of the latent space by inverting an image into the latent space to obtain its latent code.
The series is structured into the following four parts:
- Part I — Introduction to GAN Inversion and its approaches.
- Part II, III & IV — GAN Inversion extensions, applications, and future work.

In Part I, we briefly introduced the concept of GANs and their latent spaces, in addition to introducing the concept of GAN Inversion [1] and its approaches and showed a brief comparison with VAE-GANs.
In Part II, we discussed the characteristics of GAN inversion as well as latent space navigation using the technique.
In this post, which is the third part of a four-part series on GAN Inversion, we’ll discuss on some recent extensions to GAN inversion approaches.
1. Extensions to GAN inversion approaches
1.1 In-domain GAN inversion for Real Image Editing
Previous approaches attempted to reconstruct input images at a pixel level to obtain their corresponding latent vector. They, however, fail to obtain semantically meaningful latent codes within the original latent space. This means that the obtained latent code may not lie in the original latent space of the GAN or wouldn’t hold the semantic meaning encoded in the GAN latent space. Hence, making it difficult to perform semantic editing on the reconstructed image. For example, performing semantic editing on the latent space of Image2StyleGAN [4] resulted in unrealistic images for age, expression, and eyeglasses as can be seen in the image below.

In [2], the authors proposed an in-domain GAN inversion approach to obtain a latent code with the ability to reconstruct an image both at a pixel and a semantic level; suggesting that the reconstructed image not only matches at a pixel level but its corresponding latent vector lies within the latent space of the GAN holding enough semantic meaning to perform image manipulation. Their approach comprises of two phases:
- Firstly, they train a domain-guided encoder on real-image datasets instead of GAN-generated images. While reconstructing input images at the pixel level, they also regularize the training by incorporating features extracted from VGG on the images. The encoder also competes with the discriminator to ensure the obtained code generates realistic images.


- They then perform domain-regularized optimization to improve the initial latent vector obtained from the encoder by further regularizing the training with features obtained from VGG and the latent code obtained from the encoder.


Zhu et al. [2] performed semantic analysis on the latent space. Their approach was able to encode more semantically meaningful information in the latent space as compared to the state-of-the-art model GAN inversion approach, Image2StyleGAN [4], on various evaluation metrics, including Frchet Inception Distance (FID) [8] and Sliced Wasserstein Discrepancy (SWD) [7]. Their approach was also able to achieve leading performance on image reconstruction quality metrics while being ~35x faster during optimization due to better initialization. Their image reconstruction results can be seen in Fig. 4 below.

The results for facial image inversion and manipulation can be seen in Fig. 5.
While inversion using Image2StyleGAN displays slightly better results than the in-domain approach, both at image-level and the results reported for the evaluation metric MSE by [2], the interpretable directions navigation with in-domain inversion achieves much better results. Our understanding is that reconstructing images at a pixel level might result in an out-of-domain latent vector, hence failing to generate realistic images when moving in interpretable directions.

1.2 Force-in-domain GAN inversion
While In-domain GAN inversion incorporates the semantic information in the real image space, analysis by [5] shows that their inverted latent vectors do not overlap with the latent space distribution of the GAN. Additionally, the authors of [2] found some irregular image reconstruction results with their approach and later proposed In-domain inversion with batch normalization to fix the issue. However, that still did not fix the initial problem regarding the deviation from the latent space distribution of the GAN. In order to visualize the latent code distributions, the authors perform dimensionality reduction to obtain a 2-dimensional vector for the latent codes. Fig. 6 illustrates the result for the visualization.
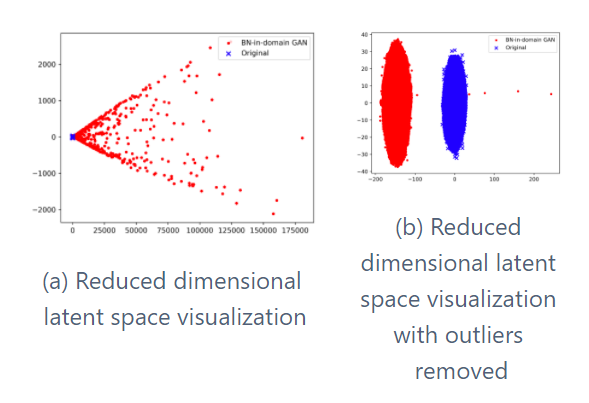
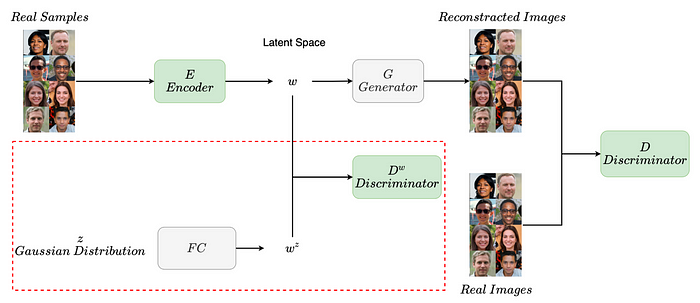
To tackle the aforementioned problem, [5] propose force-in-domain GAN inversion to incorporate semantic information in both the real image and latent code domains. They do so by including an additional discriminator to force the latent code within the latent space domain. Their proposed approach can be seen in Fig. 7. They adopt the generator G and FC block from a pre-trained StyleGAN [9] model, while the encoder E and discriminators D and Dʷ are trainable modules during inversion. The FC block maps from Z to W space, incorporating a more disentangled latent space. While training the trainable modules, E aims to reconstruct the image at both pixel and semantic levels, fooling the discriminator D, which intends to differentiate between real and reconstructed images. Dʷ tries to distinguish between the latent codes generated by E from the ones sampled in the Z space and mapped to the W space, forcing E to generate latent codes that will fool Dʷ and overlap with the latent space domain.
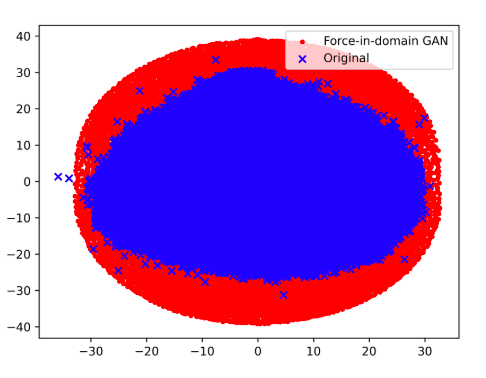
The visualization of the latent space for force-in-domain GAN inversion can be seen to overlap with the original distribution in Fig. 8.
They also report lower MSE and FID scores compared to [2], indicating better reconstruction and closer distributions. They also perform linear interpolation on inverted codes of the two input images to generate a smooth transition between the two. Fig. 9 illustrates their results from inversion and interpolation.

1.3 Image processing using Multi-code GAN prior
Previous approaches perform optimization or train an encoder to invert an image, but the generation is far from ideal. Due to the highly non-convex nature of the optimization approach, Gu et al. [3] suggests that a single latent code does not suffice in fully recovering every detail of an image.
A single latent vector also mentions the challenges due to the finite dimensionality and limited expressiveness of a latent code, and suggest an over-parameterization of the latent space to help in better reconstruction with an expectation that each latent code will reconstruct certain sub-regions of the image.
They propose mGANprior, also called multi-code GAN prior, that performs GAN inversion by incorporating multiple (N) latent codes. Linearly blending images generated by passing multiple latent codes through the generator G will not ensure a meaningful reconstructed image due to non-linearity in the image space. It was also shown by Bau et al. [6] that different units (channels) in the intermediate layers of the generator are responsible for different semantics in the image. Please refer to the GAN dissection section below for more details.
Hence, [3] suggests extracting feature maps from intermediate generator layers and introducing adaptive channel importance parameters. Similarly to [6], this is done by incorporating trainable parameters to determine the importance of each channel in the feature map. Fig. 10 shows their proposed approach.
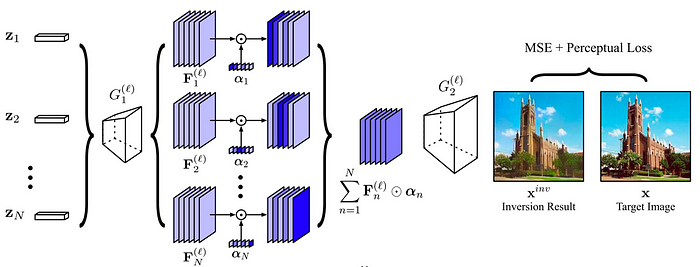
GAN inversion proves to be easier on the intermediate space rather than the latent space. They formulate the optimization as:
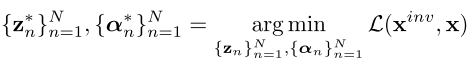
where
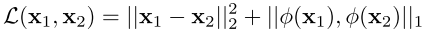
and φ represents the perceptual feature extractor.
Fig. 11 shows the effect of the number of latent codes and selection of intermediate layer on the GAN inversion task.

They experiment on various image processing applications, including colourization, super-resolution, image in-painting, etc. Fig. 12 illustrates their results.

It is also notable that their model can generalize to other datasets. For example, they optimized the inversion parameters on a face dataset but could perform inversion and reconstruct bedroom images successfully.

We experiment with the open-source code base provided by the author. With the default settings of 20 latent codes and 3000 iterations, it takes almost ~10 minutes to process each task on a NVIDIA TITAN X GPU, and hence is not suitable for real-time use cases.
2. Summary
In this post, we discussed some recent extensions to GAN Inversion such as In-domain GAN inversion, Force-in-domain and mGANprior. In the next and final part, we shall discuss applications and future work in GAN Inversion.
Read GAN Inversion: A brief walkthrough — Part IV here
References
[5] Leng, G., Zhu, Y., & Xu, Z.J. (2021). Force-in-domain GAN inversion. ArXiv, abs/2107.06050.
Written by: Sanjana Jain, AI Researcher, and Sertis Vision Lab Team
Originally published at https://www.sertiscorp.com/
