This series intends to explain the concept of GAN Inversion [1], which aims to provide an intuitive understanding of the latent space by inverting an image into the latent space to obtain its latent code.
The series is structured into the following four parts:
- Part I — Introduction to GAN Inversion and its approaches.
- Part II, III & IV — GAN Inversion extensions, applications, and future work.

In Part I, we briefly introduced the concept of GANs and their latent spaces, in addition to introducing the concept of GAN Inversion [1] and its approaches and showed a brief comparison with VAE-GANs.
In this post, which is the second part of a four-part series on GAN Inversion, we discuss the characteristics of GAN inversion as well as latent space navigation using the technique.
1. Characteristics of GAN inversion
Semantic Aware
The GAN’s latent space encodes rich semantic information. Some GAN inversion approaches aim to obtain semantic-aware latent codes to improve image manipulation. Zhu et al. [2] proposed reconstructing images at both pixel- and semantic-level for better semantic awareness. Leng et al. [8] proposed improving this further by incorporating the semantic information in both the real image and latent space domains.
Layer-wise
With larger GAN generator architectures, it is not always feasible to perform full GAN inversion. Some approaches propose to decompose the generator into layers and perform layer-wise inversion instead. Bau et al. [6] proposed using layer-wise inversion to understand what GANs learn, Bau et al. [7] proposed to visualize what GANs don’t learn, while Gu et al. [3] used this idea to perform GAN inversion with multiple latent codes.
Out of distribution
Some approaches support out-of-distribution generalization for inverting images out of the training data distribution. Gu et al. [3] aims to support out-of-distribution GAN inversion by optimizing for multiple latent codes.
We will be exploring some of these researches in more detail in the following parts of this series. But for now, let’s explore latent space navigation together with GAN inversion.
2. Latent space navigation
The survey on GAN inversion, [1], mentions that well-trained GANs have the ability to encode disentangled semantics (decoupling entangled semantics, e.g., older people tend to wear glasses more than younger people) in their latent space. With more disentangled semantic information encoded, it would be possible to find disentangled directions in the latent space referring to age and glasses. These are very useful for image manipulation tasks.
Interpretable directions
Many GAN inversion approaches aim to determine interpretable directions in the latent space. Some learning-based inversion approaches incorporate a pre-trained classifier to identify boundaries in the latent space for different classes based on synthesized images. Such supervised approaches could be restrictive. Hence, recently, an unsupervised approach has been explored, focusing on identifying interpretable directions without pre-labelled data (e.g., using PCA to identify important directions or closed-form approaches).

Numerous researches enforce disentanglement to obtain better interpretable directions in the latent space for attributes (e.g., gender, age, hair color in face images). Jahanian et al. [5] suggested an approach to steer in interpretable directions, linear and non-linear, in the GAN latent space for meaningful geometric transformation (e.g., zoom, shift, color manipulation) without enforcing disentanglement during GAN training. They observed that these interpretable directions have similar effects across all object classes generated by the GAN.
Nurit et al. [4] noticed that the output of the first layer of the generator is a coarse representation of the generated image. Hence, applying a meaningful geometric transformation on the first layer output is similar to applying it to the original image itself. They show that containing this problem to a single layer can help obtain interpretable directions in a closed-form, referring to computing interpretable directions without any training or optimization using just the generator’s weights. They investigate the unsupervised exploration of the transformations in the latent space using PCA. However, it still remains an open problem for extracting attributes such as gender and age in the latent space, requiring training or optimization.
Non-interference
When moving in a particular semantic direction in the latent space of GANs, due to entanglement between different semantics in the space, it is challenging to perform manipulation without interference. Some approaches aim to incorporate non-interference by finding orthogonal directions through projection in the latent space or incorporating a semantic space into their architecture to obtain more linearly separable attributes. These are very useful for performing multi-attribute image manipulation without interference.
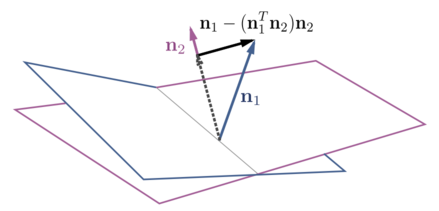
Shen et al. [11] performs conditional manipulation in the sub-space to find orthogonal semantic directions to support non-interference. Conditional manipulation refers to obtaining directions in the latent space to support decoupling between coupled attributes. Their approach can be seen in Fig. 2. With hyper-planes defining separation boundaries for semantic attributes, n₁ and n₂ represent the unit normal vectors from two hyper-planes, and n₁ — (n₁ᵀn₂)n₂ represents the new orthogonal semantic direction.
The results from their conditional manipulation can be seen in Fig. 3.

Voynov et al. [9] and Ramesh et al. [10] use Jacobian decomposition to identify more disentangled directions within the latent space.
3. Summary
In this post, we discussed the characteristics of GAN Inversion as well as the get an intuitive explanation behind latent space navigation. In the next parts, we shall discuss the recent applications and extensions of GAN Inversion.
Read GAN Inversion: A brief walkthrough — Part III here
References
[8] Leng, G., Zhu, Y., & Xu, Z.J. (2021). Force-in-domain GAN inversion. ArXiv, abs/2107.06050.
Written by: Sanjana Jain, AI Researcher, and Sertis Vision Lab Team
Originally published at https://www.sertiscorp.com/
