This series aims to explain the mechanism of Vision Transformers (ViT) [2], which is a pure Transformer model used as a visual backbone in computer vision tasks. It also points out the limitations of ViT and provides a summary of its recent improvements.

In Part I, we briefly introduced the concept of Transformers [1] and explained the mechanism of ViT and how it uses the attention module to achieve state-of-the-art performance on computer vision problems.
Although ViT has gained a lot of attention from researchers in the field, many studies have pointed out its weaknesses and proposed several techniques to improve ViT. This post, which is the second part of a three-part series, aims to describe the following key problems in the original ViT:
- A requirement of a large amount of data for pre-training.
- High computational complexity, especially for dense prediction in high-resolution images.
Additionally, this post introduces recently published papers that aim to cope with the above problems.
1. A requirement of a large amount of data for pre-training
Pre-training seems to be a key ingredient in several Transformer-based networks; however, as shown in the paper of the original ViT [2] and in other succeeding papers [3], [6]. ViT requires a very large amount of image data to pre-train in order to achieve a competitive performance, compared with CNNs. As reported in [2], pre-training ViT on the ImageNet-21k (21k classes and 14M images) or JFT-300M (18k classes and 303M high-resolution images) could lead to such a performance, while the ImageNet-1k (1k classes and 1.3M images) could not. However, pre-training a ViT on those large-scale datasets would consume an extremely long computational time and high computing resources. Moreover, the JFT-300M dataset is an internally used Google dataset, which is not publicly available.
Some approaches have been proposed so far to handle this problem. For example, in [3], a knowledge distillation technique with a minimal modification of the ViT architecture was adopted in the training process; in [6], a more effective tokenization process to represent an input image was proposed; or in [4] some modifications in the architecture of ViT were explored. The details of these approaches are explained in the following subsections.
1.1 DeiT
An idea to improve the training process of ViT is to exploit knowledge distillation as proposed in [3]. Knowledge distillation aims to transfer knowledge from a bigger model, i.e., a teacher network, to a smaller, target model, i.e., a student network. In [3], they slightly modify the architecture of ViT by appending another extra token called a distillation token, as shown in Fig. 1. The modified ViT, named data-efficient image Transformer or DeiT, generates two outputs: one at the position of the classification token which is compared with a ground truth label, and another at the position of the distillation token which is compared with the logit output from the teacher network. The loss function is computed from both outputs, which allows the model to leverage the knowledge from the teacher while also learning from the ground truths. They also incorporate some bag of tricks including data augmentation and regularization to further improve the performance. With this technique, they reported that DeiT could be trained a single 8-GPU node in three days (53 hours for pre-training and 23 hours for optional fine-tuning) while the original ViT required 30 days to train with an 8-core TPUv3 machine.

1.2 CaiT
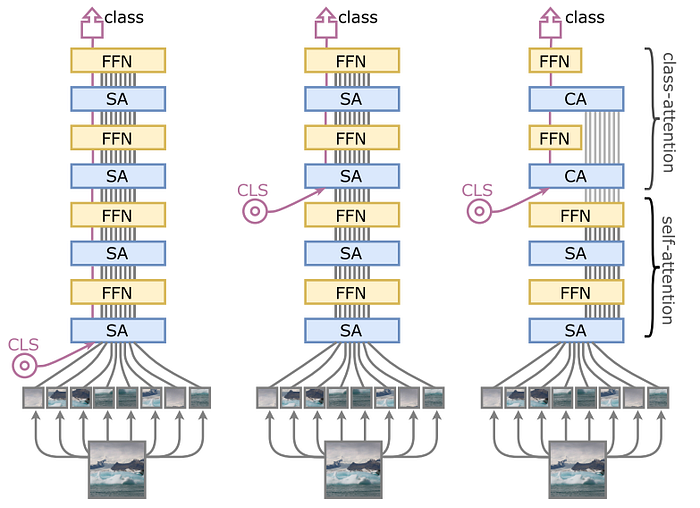
Class-attention in image Transformer (CaiT), a modified ViT proposed in [4], has been shown to be able to train on the ImageNet-1k dataset while achieving competitive performance. CaiT is different from ViT in three points. First, it utilizes a deeper Transformer, which aims to improve the representational power of features. Second, a technique called LayerScale is proposed to facilitate the convergence of training the deeper Transformer. LayerScale introduces a learnable, per-channel scaling factor, which is inserted after each attention module to stabilize the training of deeper layers. This technique allows CaiT to gain benefit from using the deeper Transformer, while there is no evidence of improvement when increasing the depth in ViT or DeiT. Third, CaiT applies different types of attention at different stages of the network: the normal self-attention (SA) in the early stage and class-attention (CA) in the later stage. The reason is to separate two tasks with contradictory objectives from each other. As shown in Fig. 2 (right), the class token is inserted after the first stage, which is different from ViT. This allows the SA to focus on associating each token to each other, without the need of summarizing the information for the classification. Once the class token is inserted, the CA, then, integrates all information into it to build a useful representation for the classification step.
1.3 Tokens-to-Token ViT
As reported in [6], the followings are the key reasons that ViT requires pre-training on a large-size dataset. The first reason is that the simple tokenization process in ViT cannot well capture important local structures in an input image. The local structures such as edges or lines often appear in several neighboring patches, rather than one; however, the tokenization process in ViT simply divides an image into non-overlapping patches, and independently converts each into an embedding. The second reason is that the Transformer architecture used in the original ViT was not well-designed and optimized, leading to redundancies in the feature maps.
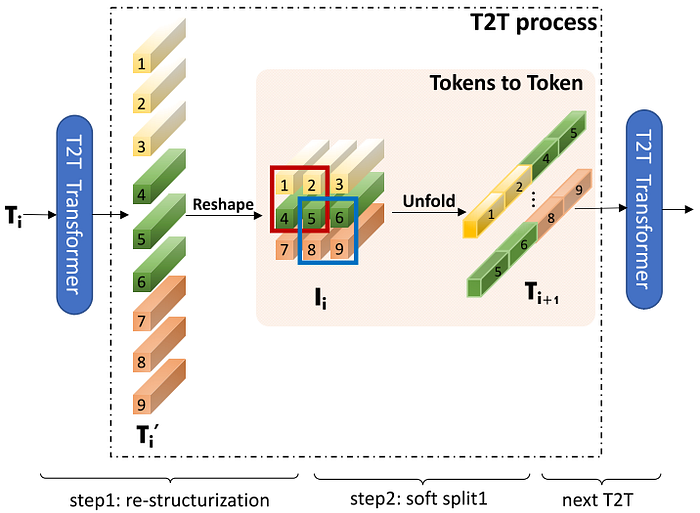
To cope with the first problem, they proposed a tokenization method, named Tokens-to-token (T2T) module, that iteratively aggregates neighboring tokens into one token using a process named T2T process, as shown in Fig. 3. The T2T process can be done as follows:
- A sequence of tokens is passed into a self-attention module to improve the relation between tokens. The output of this step is another sequence of the same size as its input.
- The output sequence from the previous step is reshaped back into a 2D-array of tokens.
- The 2D-array of tokens is then divided into overlapping windows, in which neighboring tokens in the same window are concatenated into a longer token. The result of this process is a shorter 1D-sequence of higher-dimensional tokens.
The T2T process can be iterated to better improve the representation of the input image. In [6], it was done twice in the T2T module.
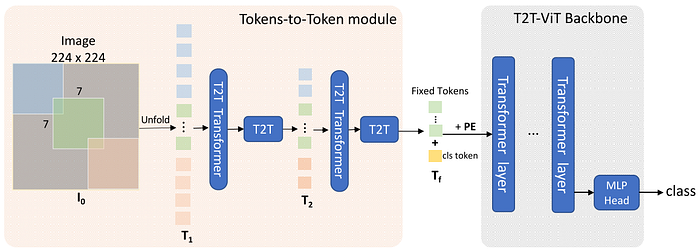
Apart from using the proposed T2T module to improve the representation of an input image, they also explored various architecture designs used in CNNs and applied them to the Transformer backbone. They found that a deep-narrow structure, which exploits more Transformer layers (deeper) to improve feature richness and reduces the embedding dimension (narrower) to maintain the computational cost, gave the best results among the compared architecture designs. As shown in Fig. 4, the sequence of tokens generated by the T2T module is prepended with a classification token, as in the original ViT, and is then fed into the deep-narrow Transformer, which is named T2T-ViT backbone, to make a prediction.
It is shown in [6] that when trained from scratch, T2T-ViT outperforms the original ViT on the ImageNet1k dataset while reducing the model size and the computation cost by half.
2. High computational complexity, especially for dense prediction in high-resolution images
Besides the requirement of pre-training on a very large-scale dataset, the high computational complexity of ViT is another concern since its input is an image, which contains a large amount of information. To better exploit the attention mechanism to an image input, pixel-level tokenization, i.e., to convert each pixel into a token, seems to be the best case; however, the computational complexity of the attention module, which is quadratic to the image size, leads to the intractable problem of high computational complexity and memory usage. Even in [2], in which images of a normal resolution were experimented with, non-overlapping patches of size 16x16 were chosen which could reduce the complexity of the attention module by a factor of 16x16. This problem is worse when ViT is applied to be a visual backbone for a dense prediction task such as object detection or semantic segmentation since high-resolution image inputs would be preferable to achieve a competitive performance with the state-of-the-art.
Several approaches to this problem mainly aim at improving the efficiency of the attention module. The following subsections describe two examples of the approaches applying to ViT [5], [7].
2.1 Spatial-reduction attention (SRA)
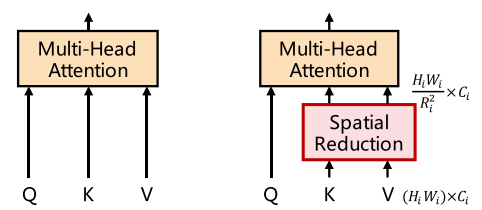
Spatial-reduction attention or SRA was proposed in [5] to speed up the computation of Pyramid Vision Transformer (PVT). As shown in Fig. 5, SRA reduces the dimension of the key (K) and value (V) matrices by a factor of Ri2., where i indicates the stage in the Transformer model. The spatial reduction consists of two steps: 1) concatenating neighboring tokens with a dimension Ci in a non-overlapping window of size Ri x Ri into a token of size Ri2Ci, and 2) linearly projecting each of the concatenated tokens to a token of dimension Ci and performing normalization process. The time and space complexities decrease because the number of tokens is reduced by the spatial reduction.
2.2 FAVOR+
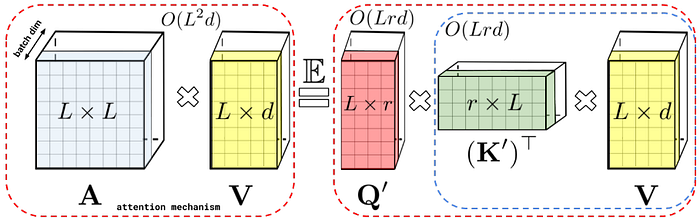
FAVOR+, standing for fast attention via positive orthogonal random feature, was proposed in [7] as a key module of a Transformer architecture named Performer. FAVOR+ aims to approximate the regular attention with a linear time and space complexity. The OR+ part in FAVOR+ was done by projecting the queries and keys onto a positive orthogonal random feature space. The FA-part in FAVOR+ was done by changing the order of computation in the attention module, shown in Fig. 6. In a regular attention module, the query and the key matrices are firstly multiplied (which requires quadratic time and space complexity), followed by multiplication with the value matrix. FAVOR+, on the other hand, approximates the regular attention by firstly multiplying the key with the value matrices, followed by the left-multiplication with the query matrix. This results in linear time and space complexity, as shown in Fig. 6.
The Performer architecture, which exploits FAVOR+ inside, was also explored in the T2T-ViT [6] and was found competitive in the performance, compared with the original Transformer, while reducing the computation cost.
3. Summary
In this post, we discussed two of the main problems of the vanilla ViT and the different solutions that have been proposed to resolve these issues. In the next and the final part, we will describe the incapability of vanilla ViT in generating multi-scale feature maps and the respective solutions that have been developed.
Read Vision Transformers: A Review — Part III here
References
[1] A. Vaswani, N. Shazeer, N. Paramr, J. Uszkoreit, L. Jones, A.N. Gomez, et al., “Attention is all you need,” Proceedings of 31st International Conference on Neural Information Processing Systems (NIPS 2017), 2017. (Original Transformer)
[7] K. Choromanski, V. Likhosherstov, D Dohan, X. Song, A. Gane, T. Sarlos, et al., “Rethinking attention with performers,” arXiv Preprint, arXiv2009.14974, 2020. (Performer and FAVOR+)
Written by Ukrit Watchareeruethai, Senior AI Researcher, and Sertis Vision Lab team
Originally published at https://www.sertiscorp.com/
