This series aims to explain the mechanism of Vision Transformers (ViT) [2], which is a pure Transformer model used as a visual backbone in computer vision tasks. It also points out the limitations of ViT and provides a summary of its recent improvements.

In Part I, we briefly introduced the concept of Transformers [1] and explained the mechanism of ViT and how it uses the attention module to achieve state-of-the-art performance on computer vision problems.
In Part II, we discussed the following two key problems in the original ViT:
- A requirement of a large amount of data for pre-training.
- High computational complexity, especially for dense prediction in high-resolution images.
Additionally, the previous part introduced recently published papers that aim to cope with the above problems.
This post, which is the third and the final part of a three-part series, aims to describe the remaining key problem of generating multi-scale feature maps in the vanilla ViT.
1. Incapability of generating multi-scale feature maps
By design, ViT, which simply uses the original Transformer encoder to process image data, can only generate a feature map of a single scale. However, the significance of multi-scale feature maps has been demonstrated in several object detection and semantic segmentation approaches. Since, in those tasks, objects of various scales (small-, mid-, or large-sizes) may appear in the same image, the use of a single-scale of feature maps might not be able to effectively detect all of the objects. Usually, large objects can be easily detected at a rough scale of the image, while small objects are often detected at a finer scale.
Several papers proposed to modify the architecture of ViT to generate multi-scale feature maps and demonstrated their effectiveness in object detection and segmentation tasks [3], [5].
1.1 Pyramid Vision Transformer (PVT)
Pyramid Vision Transformer (PVT) [3] was proposed as a pure Transformer model (convolution-free) used to generate multi-scale feature maps for dense prediction tasks, like detection or segmentation. PVT converts the whole image to a sequence of small batches (4x4 pixels) and embeds it using a linear layer (patch embedding module in Fig. 1). At this stage, the size of the input is spatially reduced. This embedding is then fed to a series of Transformer encoders to generate the first-level feature map. Next, this process is repeated to generate higher-level feature maps.
It has been shown to be superior to CNN backbones with a similar computing cost on classification, detection, and segmentation tasks. Comparing to ViT, PVT is more suitable in terms of memory usage and achieves higher prediction performance on dense prediction tasks which require higher resolution images and smaller patch size.

1.2 Swin Transformer
Another approach for generating multi-scale feature maps, named Swin Transformer, was proposed in [5]. As shown in Fig. 2, Swin Transformer can progressively produce feature maps with a smaller resolution while increasing the number of channels in the feature maps. Note that Swin Transformer adopts a smaller patch size of 4 x 4 pixels, while the patch size of 16 x 16 pixels is used in the original ViT. The key module that changes the resolution of a feature map is the patch merging module at the beginning of each stage, except stage 1. Let C denote the dimension of an embedding output of stage 1. The patch merging module simply concatenates embedding representing each patch in a group of 2 x 2 patches, resulting in a 4C-dimensional embedding. A linear layer is then used to reduce the dimension to 2C. The number of embeddings after patch merging is reduced by a factor of 4, which is the group size. The merged embeddings are then processed by a sequence of Transformers, named Swin Transformer blocks. This process is then repeated in the following stages to generate a smaller-resolution feature map. The outputs from all stages form a pyramid of feature maps representing features in multi-scales. Note that Swin Transformer follows the architectural design of several CNNs, in which the resolution is reduced by a factor of 2 on each side while doubling the channel dimension when going deeper.
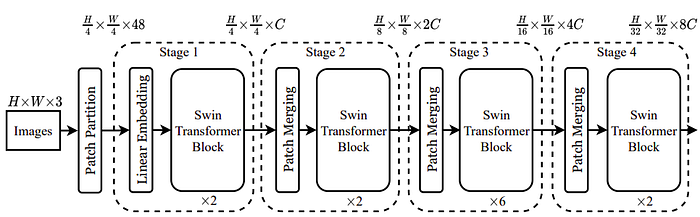
A Swin Transformer block, as shown in Fig. 2, consists of two Transformer layers: the first with a window-based MSA (W-MSA) module and the second with shifted-window MSA (SW-MSA) module. Both W-MSA and SW-MSA compute self-attention locally within each non-overlapping window, i.e., a group of neighboring patches), as shown in Fig. 3. The difference between W-MSA and SW-MSA is that the grid of windows is shifted by half of the window size. On the one hand, by limiting the attention to be inside the window, the computational complexity is linear if the window size is fixed. On the other hand, it destroys a key property of attention in ViT in which each patch can be globally associated with each other in one attention process. The Swin Transformer solves this problem by alternating between W-MSA and SW-MSA in two consecutive layers, allowing the information to propagate to a larger area when going deeper.
Experimental results in [5] showed that the Swin Transformer outperformed ViT, DeiT, ResNe(X)t in three main vision tasks, i.e., classification, detection, segmentation.


1.3 Pooling-based Vision Transformer (PiT)
A design principle of CNNs, in which as the depth increases, the spatial resolution decreases while the number of channels increases, has been widely used in several CNN models. Pooling-based Vision Transformer (PiT) proposed in [4] has shown that the design principle is also beneficial to ViT. As shown in Fig. 4, in the first stage of PiT, the input sequence of tokens is processed in the same as ViT. However, after each stage, the output sequence is reshaped into an image which is then reduced in the spatial resolution by a depthwise convolution layer with a stride of 2 and 2C filters where C is the number of input channels. The output is then reshaped back into a sequence of tokens and passed to the following stage.

Experimental results showed that the proposed pooling layer significantly improved the performance of ViT on image classification and object detection tasks. Although the experiments in [4] did not explore the use of multi-scale feature maps in those tasks, by the design of PiT, it is obviously capable of constructing a multi-scale feature map as in other models explained in this section.
2. Summary
This series on ViT aimed at summarizing the key technical details of ViT, i.e., a pure Transformer backbone which gains a lot of attention from researchers in the field. This series also points out the key problems in the vanilla ViT and introduces recent research papers that made attempts to address the problems. Due to its impressive performance, ViT and its variants are considered as a promising visual backbone for several vision tasks such as classification, object detection, or semantic segmentation, while still having room for further improvements.
References
[1] A. Vaswani, N. Shazeer, N. Paramr, J. Uszkoreit, L. Jones, A.N. Gomez, et al., “Attention is all you need,” Proceedings of 31st International Conference on Neural Information Processing Systems (NIPS 2017), 2017. (Original Transformer)
[5] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., “Swin Transformer: Hierarchical Vision Transformer using shifted windows,” arXiv Preprint, arXiv2103.14030, 2021. (Swin Transformer)
Written by: Ukrit Watchareeruethai, Senior AI Researcher, and Sertis Vision Lab team
Originally published at https://www.sertiscorp.com/
