This series aims to explain the mechanism of Vision Transformers (ViT) [2], which is a pure Transformer model used as a visual backbone in computer vision tasks. It also points out the limitations of ViT and provides a summary of its recent improvements. The posts are structured into the following three parts:

This post is the first part of a three-part series on ViT. It aims to introduce briefly the concept of Transformers [1] and explain the mechanism of ViT and how it uses the attention module to achieve state-of-the-art performance on computer vision problems.
1. What is Transformer?
Transformer networks [1] are sequence transduction models, referring to models transforming an input sequence into an output sequence. The Transformer networks, comprising of an encoder-decoder architecture, are solely based on attention mechanisms. We will be discussing attention mechanisms in more detail in the following sections. However, let’s first briefly go through some of the previous approaches.
Transformers were first introduced in [1] for the task of machine translation, referring to the conversion of a text sequence in one language into another language. Before the discovery of this breakthrough architecture, deep neural architectures such as recurrent neural network (RNN) and convolutional neural networks (CNN) have been used extensively for this task. RNNs generate a sequence of hidden states based on the previous hidden states and the current input. The longer the sentences are, the lower relevance to the words far away is left. However, in languages, linguistic meaning holds more relevance as compared to proximity. For example, in the following sentence:
“Jane is a travel blogger and also a very talented guitarist.”
the word “Jane” has more relevance to “guitarist” than the words “also” or “very”. While LSTMs, a special kind of RNNs, learn to incorporate important information and discard irrelevant information, they also suffer from long-range dependencies. Moreover, the dependence of RNNs on previous hidden states and required sequential computation does not allow for parallelization. The Transformer models solve these problems by using the concept of attention.
As mentioned previously, the linguistic meaning and context of words are more relevant than words being in close proximity. It is also important to note that every word in a sentence might be relevant to some other word in the sentence and this needs to be taken into account. The attention module in the Transformer models aims to do just this. The attention module takes as input the query, keys, and value vectors. The idea is to compute a dot product between a word (query) and every word (key) in the sentence. These provide us with weights on the relevance of the key to the query. These weights are then normalized and softmax is applied. A weighted sum is then computed by applying these weights to the corresponding words in the sentence (value), to provide a representation of the query word with more context.
It is worth noting that these operations are performed on the vector representation of the words. The words can be denoted as a meaningful representation vector, their word embeddings of N-dimension. However, as Transformer networks support parallelism, a positional encoding of the word is incorporated to encode the position of the word in the sentence. The positional information is important in many scenarios, for example, correct word ordering gives meaning to the sentence. As self-attention operation in Transformers is permutation-invariant, the positional information is introduced by adding a positional encoding vector to the input embedding. This vector captures the position of the word in the input sentence and helps to differentiate words that appear more than once. The positional embedding can either be learned embedding or pre-defined sinusoidal functions of different frequencies. A detailed empirical study of position embedding in NLP can be found here [3]. Similarly, the use of positional embedding in ViT is to leverage positional information in the input sequence.
The overview of the Transformer is shown in Fig. 1. An input sequence is fed into the Transformer encoder (the left part of the figure), which consists of N encoder layers. Each encoder layer consists of two sublayers: 1) multi-head self-attention and 2) position-wise feedforward network (PFFN). Residual connection and layer normalization are then applied to both sublayers. The multi-head attention aims to find the relationship between tokens in the input sequence in various different contexts. Each head computes attention by linearly projecting each token into query, key, and value vectors. The query and key are then used to compute the attention weight which is applied to the value vector. The output from the multi-head attention sublayer (the same size as its input) is then fed into PFFN to further transform the representation of the input sequence. This process is repeated N times by N encoder layers.
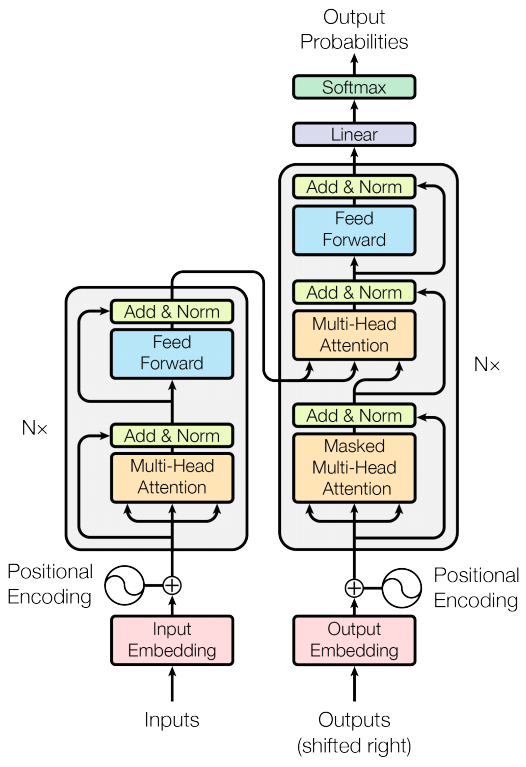
The right part of the figure is the Transformer decoder, similarly consisting of N decoder layers, attached by a prediction head (the linear layer with softmax). Each decoder layer consists of three sublayers: 1) multi-head self-attention, 2) multi-head cross-attention, and 3) PFFN. The first and the third are similar to those of the encoder layers. The second sublayer, i.e., multi-head cross-attention, computes the relationship between each token in its input sequence and each token in the output generated by the encoder. In particular, as shown in the figure, the Transformer decoder receives two inputs: 1) a sequence of tokens fed into the bottom of the decoder and 2) the output from the Transformer encoder. In the original paper of the Transformer model [1], in which machine translation was considered, the output sequence generated by the prediction head is fed into the decoder as input. Note that in other applications, e.g., computer vision, an extra fixed or learnable sequence can be used as input to the decoder.
More information about the Transformer model can be found in [9], [10]. This four-video series on attention is also highly recommended [11].
2. Vision Transformer
The Transformer model and its variants have been successfully shown that they can be comparable to or even better than the state-of-the-art in several tasks, especially in the field of NLP. This section briefly explores how the Transformer model could be applied to computer vision tasks and then introduces a Transformer model, Vision Transformer (ViT), which gains massive attention from many researchers in the field of computer vision.
Several attempts have been made to apply attention mechanisms or even the Transformer model to computer vision. For example, in [4], a form of spatial attention, in which the relationship between pixels is computed, has been used as a building block in CNNs. This mechanism allows CNNs to capture long-range dependencies in an image and better understand the global context. In [5], a building block called squeeze-and-excitation (SE) block, which computes the attention in the channel dimension, was proposed to improve the representation power of CNNs.
On the other hand, the combination between the Transformer model and CNN has been proposed to solve computer vision tasks such as object detection or semantic segmentation. In Detection Transformer (DETR) [6], a Transformer model was used to process the feature map generated by a CNN backbone to perform object detection. The use of a Transformer model in DETR removes the need for hand-designed processes such as non-maximal suppression and allows the model to be trained end-to-end. Similar ideas have been proposed in [7] and [8] to perform semantic segmentation.
Distinct from those works in which a Transformer or attention modules are used as a complement to CNN models to solve vision tasks, ViT [2] is a convolution-free, pure Transformer architecture proposed to be an alternative visual backbone. The overall network architecture of ViT is shown in Fig. 2.
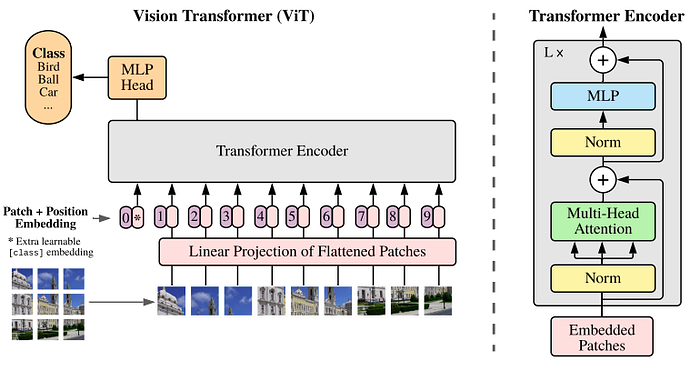
A key idea of applying a Transformer to image data is how to convert an input image into a sequence of tokens, which is usually required by a Transformer. In ViT, an input image of size H x W is divided into N non-overlapping patches of size 16 x 16 pixels, where N = (H x W) / (16 x 16). Each patch is then converted into an embedding using a linear layer. These embeddings are grouped together to construct a sequence of tokens, where each token represents a small part of the input image. An extra learnable token, i.e., classification token, is prepended to the sequence. It is used by the Transformer layers as a place to pull attention from other positions to create a prediction output. Positional embeddings are added to this sequence of N + 1 tokens and then fed into a Transformer encoder.
As shown in Figs. 1 and 2, the Transformer encoder in ViT is similar to that in the original Transformer by Vaswani et al. [1]. The only difference is that in ViT, layer normalization is done before multi-head attention and MLP while Vaswani’s Transformer performs normalization after those processes. This pre-norm concept is shown by [12], [13] to lead to efficient training with deeper models.
The output of the Transformer encoder is a sequence of tokens of the same size as the input, i.e., N + 1 tokens. However, only the first, i.e., the classification token, is fed into a prediction head, which is a multi-layer perception (MLP), to generate a predicted class label.
In [2], ViT was pre-trained on large-scale image datasets such as ImageNet-21k, which consists of 14M images of 21k classes, or JFT, which consists of 303M high-resolution images of 18k classes, and then fine-tuned on several image classification benchmarks. Experimental results showed that when pre-trained with a large amount of image data, ViT achieved competitive performance compared to state-of-the-art CNNs while being faster to train.
3. Summary
We have briefly introduced the concept of Transformer and explained how ViT, a pure Trasnformer visual backbone, solves computer vision problems. Although ViT can gain a lot of attention from researchers in the field, many studies have pointed out its weaknesses and proposed several techniques to improve ViT. In the following parts, we describe the key problems in the original ViT and introduce recently published papers that aim to cope with the problems.
Read Vision Transformers: A Review — Part II here
References
[1] A. Vaswani, N. Shazeer, N. Paramr, J. Uszkoreit, L. Jones, A.N. Gomez, et al., “Attention is all you need,” Proceedings of 31st International Conference on Neural Information Processing Systems (NIPS 2017), 2017. (Original Transformer)
[3] Y.-A. Wang and Y.-N. Chen, “What do position embeddings learn? An empirical study of pre-trained language model positional encoding,” arXiv Preprint, arXiv2010.04903, 2020. (Positional Embedding study, NLP)
[4] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. (Non-local NN)
[10] The Illustrated Transformer
[11] Rasa Algorithm Whiteboard — Transformers & Attention
[12] Learning Deep Transformer Models for Machine Translation https://www.aclweb.org/anthology/P19-1176.pdf
[13] Adaptive Input Representations for Neural Language Modeling https://openreview.net/pdf?id=ByxZX20qFQ
Written by: Ukrit Watchareeruethai, Senior AI Researcher, and Sertis Vision Lab team
Originally published at https://www.sertiscorp.com/
