Multi-stage Pipeline Evaluation: A case study of Thai ID OCR system

Multi-stage pipeline and its challenges
Applied machine learning is typically focused on finding a single model that performs well on the real use case data. In this case, the model would be evaluated with the evaluation metrics specific to the task it performs. This helps to understand the model characteristics and the performance on a given dataset, which is beneficial for further improvement. However, in some cases, a single module does not suffice, and collaboration with the other modules is required to generate the final output, leading to a multi-stage pipeline.
In this blog post, a multi-stage pipeline is what we refer to as a machine learning pipeline where various modules collaborate, and each performs a specific task. For example, a face recognition pipeline generally comprises face detection, alignment, embedder, and verification modules to match faces to the correct identity. This brings a new challenge to the pipeline evaluation process. Since there are multiple modules in the pipeline, each of them has a different impact on the final result. An end-to-end evaluation can provide you with a general understanding of the pipeline, but it might be challenging to discern how each module affects the pipeline as a whole. In this blog post, we discuss the idea of how we tackle this issue and actually see the effect of the individual module on the entire pipeline.
At Sertis Vision Lab, we built a Thai ID OCR product requiring a multi-stage pipeline. Hence we’ll be using our Thai ID OCR pipeline as an example to showcase our approach to do an in-depth evaluation of our models.
Thai ID OCR pipeline
Our Thai ID OCR product aims to automate the extraction of information from the images containing Thai ID cards. In our pipeline, multiple modules are integrated to perform OCR on Thai ID cards, which consists of 4 main modules: card detector, text detector, text reader, and entity mapping. Please visit our OCR blog post [1] for more detail on each module.
Each of these modules plays an important role in generating the final output and determining the overall performance of the entire pipeline. Therefore, to ensure good performance at the pipeline level, it is necessary to verify the impact of each module on the pipeline performance. This allows us to focus on improving only a few modules that form the bottleneck for performance rather than trying to improve all components, which require more time and resources.
Traditional evaluation approaches
To identify the model that needs to be improved the most, we firstly focus on the two commonly used evaluation methods: individual evaluation and end-to-end evaluation.
Individual evaluation
In this method, each module is evaluated individually with different evaluation metrics. In our case, we use average precision and average recall as evaluation metrics for the card detector and the text detector, accuracy and Levenshtein distance for the text reader, and normalized mean accuracy to evaluate our entity mapping module.
Each evaluation metric reflects the real performance of each module without any influence from the other previous modules, replicating a single-stage pipeline evaluation for each module. Therefore, it could provide a basic idea of how each module performs individually. However, in a multi-stage pipeline in which multiple modules work together in a waterfall manner, the performance of upstream modules also determines the quality of the downstream module’s input. Hence, evaluating the model so that each module is completely independent is an unrealistic scenario and cannot represent how each module affects the whole pipeline.
End-to-end evaluation
Rather than evaluating each module individually with different evaluation metrics independent of other components, an end-to-end evaluation mainly focuses on the overall performance of the pipeline. Hence, it considers only the final output and uses only a few metrics corresponding to the output to measure the predictive accuracy. In our case, we use accuracy and Levenshtein distance as evaluation metrics. Therefore, the score would represent the performance of the entire pipeline as a consequence of all modules. Additionally, logging can help to identify the process in which the error occurs. However, only the error that breaks the entire pipeline would be one that could be logged. For example, when no text has been detected by the text detection module, an error would result since there would be no input for the next module. This kind of error would be reported in the log file. However, it is difficult to identify the root cause, especially if the errors occur in a downstream module. In particular, the cause of these errors could be the downstream module’s poor performance, a consequence of an underperformed upstream module, or both. With this method, the only thing you can see is how the final output is, but not the impact of each module on the entire pipeline.
The proposed solution
Due to the aforementioned problems of these two traditional evaluation methods, we propose an approach to perform an end-to-end evaluation with an ideal module. This allows us to evaluate the performance of the whole pipeline while being able to observe the contribution of each module if it were to perform ideally. As our approach evaluates the pipeline in an end-to-end manner, replacing a module with its ideal counterpart gives a better idea of the relative impact improving that module would have on the entire pipeline.
The Implementation of the end-to-end evaluation with an ideal module
To implement this solution, we replace a module’s output with its ideal annotation to simulate the situation when this module works perfectly. We then compare the evaluation score with the normal end-to-end pipeline to understand the module’s impact on the overall performance. To evaluate the pipeline performance, we use accuracy as an evaluation metric. This metric is computed for each entity over the dataset of images.
Please note that as we make the modules in the pipeline ideal, it increases the complexity of the evaluation implementation. This is because the ideal output from the module is not always its ground truth but rather the ideal annotation on the input it receives from the previous module (which is not ideal).
Here’s how we applied our proposed evaluation approach to the different modules in our Thai ID pipeline:
- End-to-end evaluation with an ideal card detection module
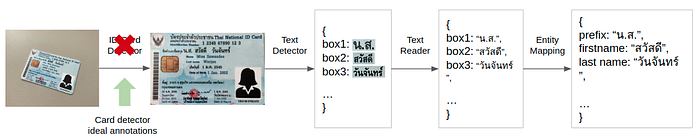
To simulate the situation where the card detector works ideally, instead of running a card detector to obtain the card corner keypoints as output, we directly use the ground truth points obtained from our manual annotations of card detection. In this way, we can understand the improvements on the overall pipeline results when the card detector works perfectly.
- End-to-end evaluation with an ideal text detection module
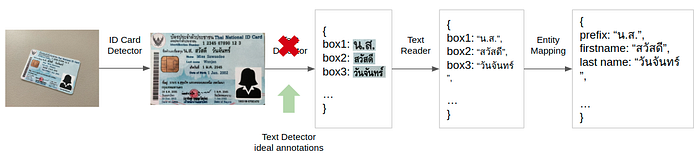
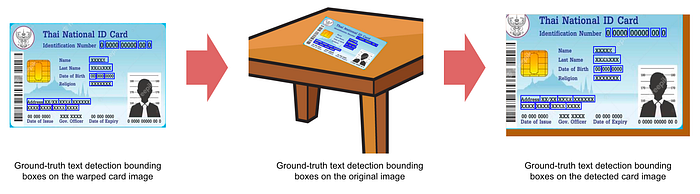
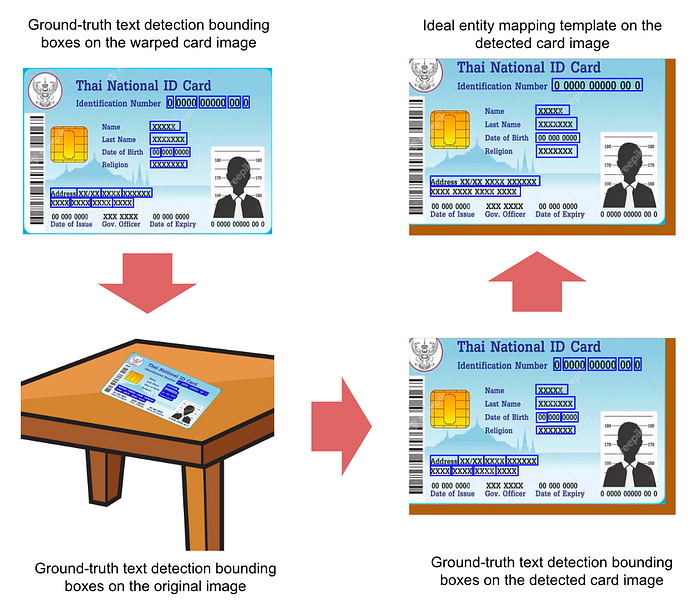
The emulation of the ideal text detector was implemented by replacing the text detection module with its ideal annotation. While we have the ground-truth text detection bounding boxes, which are manually annotated on the warped card image obtained using the ground-truth card detection keypoints. However, the card detector is not ideal. Hence, the ground-truth text detection bounding box annotations need to be transformed into the warped card image obtained from running the card detector. This is done by transforming the ground truth text detector annotations from the cropped card to the original image and then to the detected warped card image. This transformation is illustrated in Fig. 3.
- End-to-end evaluation with an ideal text reader module
This is the most complicated of the ideal module evaluations to be automated and requires manual annotations each time the previous modules get updated. Replacing the text reader module with its annotation requires us to have the ideal text reader results for any image passed to the text reader. While we have the ground truth text for the entire pipeline, it does not meet the requirement, especially in the following cases: 1) the text detector does not detect the entire bounding box; or 2) it splits the text that supposes to be in the same bounding box into multiple separated bounding boxes. It inevitably affects the results of the text reader even when the module itself can work perfectly. We hence would require character-level annotations for this evaluation for all required text on the card. This, together with the ground truth and detected text bounding boxes, would result in a better estimate of the prediction of the ideal text reader. As this requires character-level annotations, this is still to be implemented.
- End-to-end evaluation with an ideal entity mapping module
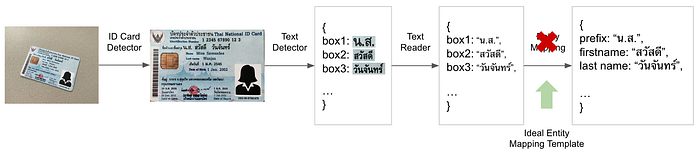
As the entity mapping module was aimed to map detection boxes from the text detector to the entity it represents, this was implemented using the entity mapping template to match the bounding box with the entity it belongs to. Simulating the ideal entity mapping module was aimed at obtaining the ideal entity mapping template for performing the mapping. While we have the ground-truth text detection bounding boxes corresponding to the ground-truth entity mapping template, which is annotated on the warped card image obtained using the ground-truth card detection keypoints. However, the card detector and text detector are not ideal. Hence, to generate the ideal entity mapping template on the detected card image, the ground-truth text detection bounding box annotations need to be transformed into the warped card image obtained from the card detector, and the ideal template for entity mapping is then generated using these transformed bounding boxes. The ideal entity mapping template generation is illustrated in Fig. 5.
The implementation results comparison
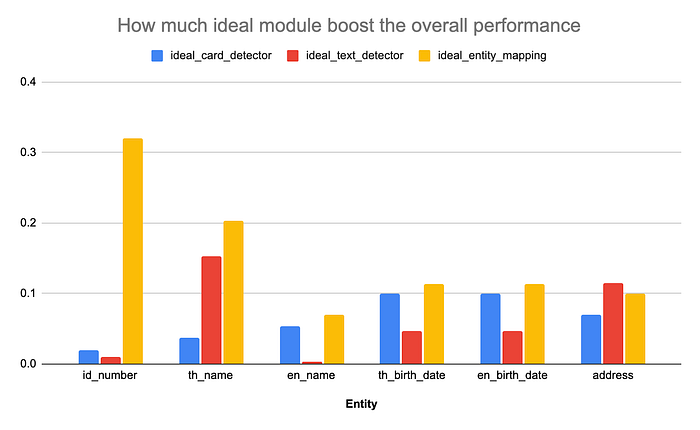
We run the end-to-end evaluation with an ideal module on a real-world dataset that we built internally (please visit the OCR blog post [1] for more information). The histogram in Fig. 6 illustrates how accuracy improves as each ideal module is individually incorporated into the pipeline. When compared to the other ideal modules, an ideal entity mapping module typically brings the largest gain in accuracy, notably for the id_number and th_name, which are the crucial information we prioritize. Overall, the accuracy averaged across all entities of the pipeline with an ideal card detection module, an ideal text detection module, and an ideal entity mapping module increases by 6.9%, 7.4%, and 12.9%, respectively. The comparison shows the contribution of each ideal module to the pipeline performance. In other words, the module that could bring the most improvement to the overall performance when it becomes an ideal one should be improved the most. Based on this comparison, we decided to improve our entity mapping module, achieving a 12.1% increase in accuracy.
Conclusion
Our proposed method of end-to-end evaluation with an ideal module utilizes the ideal annotation of each module to simulate the situation when that module can work perfectly to observe its impact on the entire pipeline. It can address the problem in the multi-stage pipeline where the individual evaluation and the normal end-to-end evaluation are not able to represent the effect of each module on the overall performance. While the proposed evaluation approach aids in all of this, we still require a standard end-to-end evaluation to fully comprehend the performance of the pipeline as a whole, and an individual evaluation to assess each module separately. By performing this proposed solution together with these two traditional evaluation methods, we can get a better understanding of our pipeline and have a clearer direction of which module should be the priority to be improved in order to boost the overall performance.
References
Written by: Sertis Vision Lab
