Whether we’re recording license plate numbers of vehicles violating traffic rules or validating the identities of individuals from identification (ID) cards, we come across various applications requiring the extraction of text information from the surroundings. While these required manual data entry decades ago, most of these processes have been automated, thanks to the advancements in computer vision and, more specifically, Optical Character Recognition (OCR).

OCR refers to the process of transforming typed or handwritten text from an image into a machine-readable format. There is a wide range of applications for OCR, including document text extraction, scene text recognition, number plate recognition, etc.
At Sertis Vision Lab, we’ve built OCR systems for various applications. In this blog post, we majorly dive into our Thai ID OCR product while giving a brief overview of our License Plate Recognition system.
Thai ID OCR
Our Thai ID OCR product aims to automate the extraction of information from images containing Thai national identification cards, supporting both front and back sides. We successfully extract various entities, including the ID number, English name, Thai name, English date of birth, Thai date of birth, address, and Laser ID.
Our OCR pipeline comprises four main modules:
- Card detector: detects the card corner points in real-world images to return the cropped card image.
- Text detector: detects the various texts on the cropped card image and outputs the coordinates of the text locations.
- Text reader: recognizes the text located in the detected text boxes to output the text in an accessible electronic format.
- Entity mapping: maps the recognized text from the text reader to the entity it represents.
Fig. 1 illustrates the overall pipeline of our Thai ID OCR system.

Modules
Card detector
This module aims to detect the four corner points of the front & back of Thai ID cards from real-world images. For our card detector, we adopt the CenterNet model architecture [1], which successfully detects the object centers and regresses the bounding box details to obtain keypoints. We train our model on a publicly available dataset of ID card images and an in-house artificially synthesized Card Detector dataset containing 5,000 images of Thai IDs. As a post-processing step, these images are cropped and resized before being passed to the text detector.
Text Detector
The text detector module aims to detect the English & Thai text regions on its input image and outputs the bounding box coordinates of the text locations. We leverage the CRAFT architecture [2] to build our text detector and adapt it to support the Thai language. While the pre-trained CRAFT model performs well on English data, it fails to capture the vowels in the Thai language, lying above and below the characters. Therefore, we fine-tune the CRAFT model on an internally built synthesized Text Detector dataset comprising 13,000 images of Thai texts in various scenes and a publicly available dataset containing text images in various languages, excluding Thai. We also make additional modifications to the architecture and the training strategy to better adapt our model for Thai texts.
Text Reader
The text reader module aims to recognize the text that appears on the input image and outputs the text in an accessible electronic version. We adopt the STR [3] model architecture for our text reader. In order to train the model, we build our own synthetic Text Reader Dataset comprising Thai & English texts in various fonts and backgrounds.
Entity Mapping
This module aims to map recognized text from the text reader to the entity it represents. With a pre-defined entity mapping template relative to the cropped and resized card image, each recognized text’s bounding box is mapped to its best matching entity based on the overlap ratio. However, this makes the mapping sensitive to the performance of the card detector. Hence, we re-align the template using additional information about the locations of recognized texts with static reference positions on the card. We also perform some post-processing steps, including checking the validity of certain entities and assigning them to the correct abbreviation to obtain the final result.
Data
In order to evaluate our model, we built an internal real-world ID card dataset of 179 images, comprising 87 simple and 92 challenging images, to better understand the model’s performance.
Admittedly the size of the dataset is really small for the scope of the problem, but this is owing to the sensitive data in the Thai ID cards, especially the back of the card. Hence, to tackle this issue, we also evaluate our model on synthetic datasets we generated in-house for Thai IDs.
Additionally, we are building a new real-world dataset with more variations to the data, e.g., occlusion, varying illumination conditions, etc., to understand the model’s performance under such conditions.
Evaluation results
Overall pipeline evaluation
In order to evaluate the overall pipeline, we use two main evaluation metrics:
- Accuracy: the entity-level accuracy computed between the overall predicted text for an entity and its corresponding ground truth. The accuracy is 1 if the predicted text matches the ground truth and 0 otherwise.
- Levenshtein distance: the minimum number of single-character edits required to transform the predicted result to the ground truth, further normalized by the length of the ground truth to obtain a value between 0 and 1.
These metrics are computed for each entity over the dataset of images.
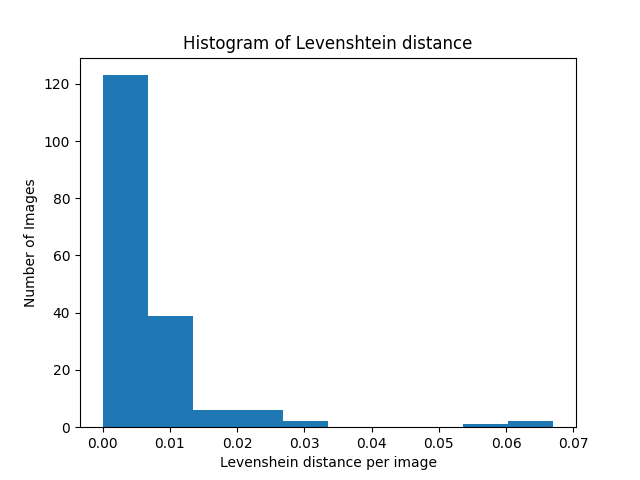
With our internal real-world dataset, we are able to achieve 97%+ accuracy for simple images and 87–99 % accuracy for challenging images for most entities. Additionally, we obtained a low Levenshtein distance per entity and per image on the entire dataset. This can be seen from the histogram of Levenshtein distance in Fig. 2, where over 85% of images have a Levenshtein distance of less than 0.02.
Individual module evaluation
In order to evaluate our card detector, the most commonly used object detection evaluation metrics are used:
- AP: the average precision rate computed over various thresholds.
- AR: the averaged maximum recall rate computed over various thresholds.
We achieve an AP of 0.94 and AR of 0.96 on our internal dataset at the Object Keypoint Similarity (OKS) of 0.5. OKS refers to a metric that quantifies the distance between predicted and ground-truth keypoints, further normalized to lie in the range of 0–1.
We also use the AP and AR metrics to evaluate our text detector. We achieved an AP of > 0.8 for most entities at an IOU (Intersection-over-Union) of 0.5, while having a reasonably acceptable AR.
For our text reader, we used the Accuracy and Levenshtein distance metrics and were able to achieve 94%+ accuracy for most entities with a low Levenshtein distance.
Finally, we use the normalized mean accuracy to evaluate our entity mapping module, achieving 98%+ accuracy on all entities.
License Plate Recognition
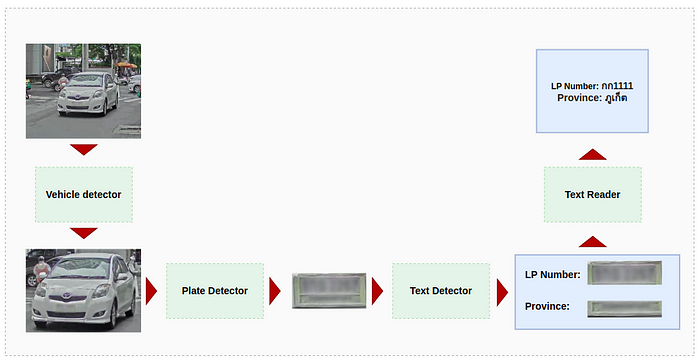
As part of our Smart City project, we developed a license plate recognition (LPR) pipeline comprising various modules similar to the Thai ID pipeline. These include the vehicle and plate detectors, the text detector, the text reader, and additional post-processing steps to output the license plate number and province of the detected vehicle. The pipeline for license plate recognition can be seen in Fig. 3.
Our model achieved 99.6% accuracy on vehicles captured in a controlled environment.
Use cases
While our current OCR pipelines are implemented for very specific products, they can effortlessly be adapted to various applications. For example, our Thai ID OCR pipeline can easily be extended to various digitally typed documents, including passports, driving licenses, etc. Similarly, our license plate OCR can be adapted for scene text recognition with minor modifications to the pipeline.
References:
[1] Zhou, X., Wang, D., Krähenbühl, P.: Objects as points. arXiv:1904.07850 (2019)
Written by: Sertis Vision Lab
