
Introduction
A face recognition (FR) system is a technology that identifies or confirms a person’s identity by detecting and analyzing facial features in an image. Development of this technology has been ongoing as early as the 1960s. However, with the advancement in machine learning research in recent years, FR systems using deep learning have become more accurate, scalable, and efficient. Nowadays, biometric security systems use FR to uniquely identify individuals during user onboarding or logins and strengthen user authentication activity.
FR can be categorized as face verification and face identification. In either scenario, a set of known subjects is initially enrolled in the system (the gallery), and a new subject (the probe) is presented during testing. While face verification requires computing one-to-one similarity between the gallery and probe to determine whether the two images are of the same subject, face identification computes one-to-many similarity to determine the specific identity of a probe face.
Typically, an FR system consists of three modules : 1) a face detector, 2) a face alignment module, and 3) a face embedding network. The face detector is used to localize faces in images or videos while the face alignment module aligns the detected faces to normalized canonical coordinates. Finally, the face embedding network, which is a deep feature extraction network, takes the detected and aligned facial images as input and creates low-dimensional vectorized representations for them. These vectors or embeddings are deep feature representations of the facial images which are used during enrollment and testing for face verification and identification.

Keeping in line with the current trend in face recognition research, Sertis Vision Lab researchers have developed the Sertis FR system. Using Sertis’ state-of-the-art (SoTA) face detection model [1] and face landmark model [2], the system is able to accurately detect faces and localize face landmarks (e.g. pupils, nose peak, mouth corners, etc.) to align the detected faces. Trained on massive data with the supervision of an appropriate loss function, the face embedding network for the Sertis FR system is inspired by typical Convolutional Neural Network (CNN) architectures, such as AlexNet [4], GoogleNet [5], VGGNet [6], ResNet [7], and SENet [8].
The performance of the Sertis FR system is on par with the current SoTA models on benchmark datasets such as LFW [9], CALFW [10], and CPLFW [11]. In addition, the system has also been independently evaluated by NIST [3]. On multiple occasions, Sertis has been ranked top 30 globally and consistently ranked number 1 in Thailand on the NIST-FRVT 1:1 Verfication leaderboard.
NIST
The National Institute of Standards and Technology (NIST), a prestigious organization under the U.S. Department of Commerce, started a new evaluation of FR technologies in February 2017. Unlike previous evaluations, the activity is conducted on an ongoing basis. The evaluation remains open indefinitely such that developers may submit their algorithms to NIST whenever they are ready. The Face Recognition Vendor Test (FRVT), conducted by NIST, is aimed at measurement of the performance of automated face recognition technologies applied to a wide range of civil, law enforcement and homeland security applications including verification of visa images, de-duplication of passports, recognition across photojournalism images, and identification of child exploitation victims. Various ongoing NIST conducted FRVT projects include:
- FRVT 1:1 Verification
- FRVT 1:N Identification
- FRVT: Face Mask Effects
- FRVT Demographic Effects
- FRVT MORPH
- FRVT PAD
- FRVT Twins Demonstration
- FRVT Paperless Travel
- FRVT Quality Summarization
In this blog-post, we shall focus on the performance of the Sertis FR system on the recent FRVT 1:1 Verification leaderboard.
FRVT 1:1 Verification
As the name suggests, the FRVT 1:1 Verification evaluation aims to measure an FR system’s performance on the verification task. The performance of an FR system is computed using the false non-match rate (FNMR) and the false match rate (FMR). The evaluation aims to test how similar the FR system infers a reference image to genuine and impostor images. While the FMR is an indicator for the FR system’s vulnerability to falsely verify an identity using reference-impostor pair, the FNMR demonstrates the system’s inability to verify an identity using reference-genuine pairs. Similarity scores between the reference-genuine pairs and reference-impostor pairs are generated based on a suitable distance metric.
Thus, given a vector of N genuine scores, u, the FNMR is computed as the proportion below some threshold, T:
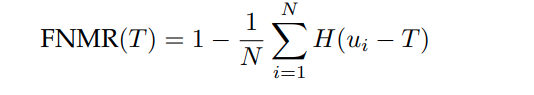
where H(x) is the unit step function, and H(0) taken to be 1.
Similarly, given a vector of N impostor scores, v, the false match rate (FMR) is computed as the proportion above T:
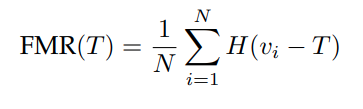
The threshold, T, can take on any value. The performance is reported in terms of the error tradeoff characteristics plots of FNMR(T) vs. FMR(T).
Dataset
We focus on the two relevant FRVT datasets which are used to give an accurate estimation of the performance of the Sertis FR system in the context of face verification.
- Visa images: The number of subjects in this category is of the order of 105. The images are of size 252x300 pixels, with the mean inter-ocular distance (IOD) being 69 pixels. The images are of subjects of all ages from greater than 100 countries, with a significant imbalance due to visa issuance patterns. Additionally, many of the images are live capture, and a substantial number of the images are paper photographs.
- Border crossing images: The number of subjects in this category is of the order of 106. The images are captured with a camera oriented by an attendant toward a cooperating subject. This is done under time constraints so there are role, pitch and yaw angle variations. Also background illumination is sometimes strong, so the face is under-exposed. There is some perspective distortion due to the close range of the images. Some faces are partially cropped. Similar to the Visa images, the images are of subjects from greater than 100 countries, with significant imbalance due to population and immigration patterns. The images have a mean IOD of 38 pixels.

Test Design
The test design for the FRVT 1:1 Verification involves cross domain verification. The comparisons are of visa-like frontals (visa images dataset described above) against border crossing webcam photos (border crossing dataset described above). The test is aimed to compare a new set of high quality visa-like portraits with a set of webcam border-crossing photos that exhibit moderately poor pose variations and background illumination. The comparisons are “cross-domain” in that an FR system must compare “visa” and “wild” images. The number of genuine and impostor comparisons is of the order of 106. The impostors are paired by sex, but not by age or other covariates.
Result
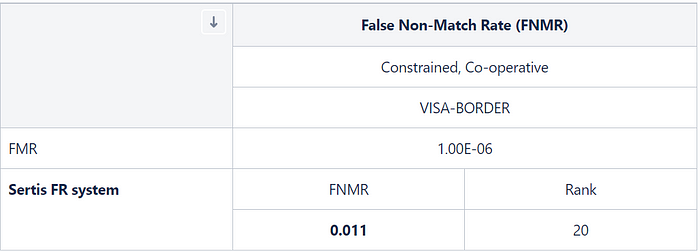
Multiple attributes of the test images (ethnicity, age, gender) can lead to hidden bias in the results if the classes are unbalanced. Hence, it is important to investigate the consistency of the results across different categories. The following table illustrates the consistency of the Sertis FR system across age and gender.
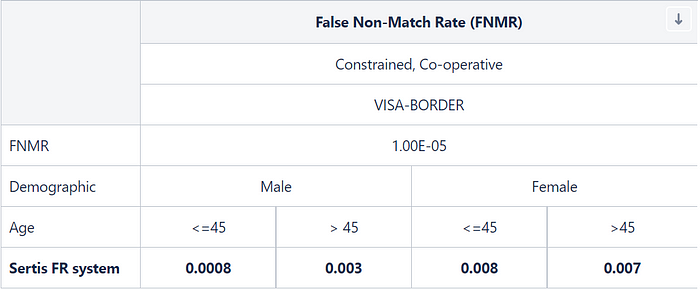
For ages > 45, the Sertis FR system has an FNMR of 0.007 and 0.003 on females and males respectively. While for ages <= 45, the system has an FNMR of 0.008 and 0.0008 on females and males respectively.
Presentation Attack Detection
Presentation Attack Detection (PAD) is crucial in applications where security and convenience are a priority, especially in automated identification and authentication scenarios such as physical access control, travel facilitation, payments, or online identity verification. In recent years, as FR systems have emerged as the dominant biometric in many applications due to their low cost, accuracy, and usability, presentation attacks or spoofs have evolved to include photographs, masks, fake silicone fingerprints, and even video replays.
Thus, the Sertis FR system offers an optional PAD module integration to make the biometric system robust against spoof attacks. The Sertis PAD module combines the following two solutions:
- Passive Liveness Detection : Passive liveness detection is a fraud detection method that does not require any specific actions from the user. The Sertis FR system requires only one snapshot, which is then analyzed using a deep learning model. Sertis Vision Lab has developed a SoTA passive liveness detection model, which has been trained on an in-house dataset captured in the wild. The model’s overall accuracy is 99.74% at a False Acceptance Rate (FAR) of 0.001.
- Active Liveness Detection : Active liveness detection requires users to intentionally confirm their presence by interacting with the system as part of the process. The Sertis FR system uses live video capture to detect user interaction with the system. The current solution captures the user blinking using Sertis’ SoTA face landmarks model [2] before sending the best frame in the video sequence to the passive liveness detection model to further check for a passive video attack. The blink counting accuracy is evaluated by computing all the frames in the captured video sequence and currently stands at 99.61% and 99.21% for 30 FPS and 15 FPS videos, respectively.
Use Case
Sertis Vison Lab has developed the Sertis Face Scan and the Sertis Face Scan Pro, which integrate the Sertis FR system and the Sertis PAD modules as solutions to biometric access control. Additionally, in the wake of the Covid-19 pandemic, these solutions also offer mask detection using Sertis’ SoTA mask detection module [13] and contactless temperature measurement to enhance safety by no longer requiring human supervision of a traditional temperature measurement device.
Read more about the various face analytics performed by the Sertis FR system here.
Check out the demo of the Sertis Face Scan here.
References:
Written by: Sertis Vision Lab
