
Artificial Intelligence (AI) has already become part of our day-to-day life, ranging from accommodating mundane tasks, like finding the best restaurant for a date night, all the way to personal assistance for critical tasks we do at work. While AI has not yet reached the level depicted in sci-fi movies, such as 2001: A Space Odyssey and Minority Report, the gap between fiction and reality is noticeably closing. A major leap arrived on November 30th, 2022, with the launch of ChatGPT by OpenAI [1], imprinting the term Large Language Model (LLM) into everyone’s mind. LLM is a family of AIs that has demonstrated unprecedented capability to comprehend human writings and respond accordingly. Since then, a plethora of brand new AIs has surfaced, for example, Google’s Gemini [2] [3] [4], Meta’s LLAMA [5] [6], Mistral AI’s Mixtral [7], and the list goes on and on. Applications of these models and use cases have also emerged, stemming from this comprehension capability. LLMs allow various applications to come true. Customers are engaging in a delightful conversation with LLM-powered customer service chatbots. Programmers are using LLM to assist with coding. Entrepreneurs and executives are utilizing LLMs to summarize world events for informed decision-making. These diverse applications stem from a single, fundamental ability: the power to “read” text. This capability, once in the realm of fiction, is now transforming our lives.
Writing and reading are essential for expressing and understanding ideas, intentions, and instructions, but words are not always the most effective means of conveying information. Visual imagery is another powerful method of communication and arguably predates spoken language.

AIs with the capability to understand images have been around for quite a while. For instance, AI can locate and highlight objects in an image (instance segmentation) and generate a short description of images (image captioning). However, these AIs are often limited to their designated tasks. Building on these accomplishments, the next logical step is to push for an AI that can perform multiple tasks, including some reasoning capabilities, akin to the LLM.


Multimodal Models represent a substantial leap forward in AI development, as they can receive input in multiple formats, such as text, images, and audio, and perform complex tasks that require understanding the input from different modalities. Multimodality enables AIs to handle tasks that were previously impossible, such as summarizing business insight from complex graphs, searching through a pile of presentation pages for specific information, and extracting information from images. Previously, individual specialized AIs were required for these tasks. For example, one AI might specialize in business graph interpretation and only provide insights based on input charts. Another AI could specialize in data extraction and only convert images into tables of numerical values. Instead, multimodality offers a single, unified application that can interpret and process information from diverse sources, including following an instruction to perform a specific task for a user.

Multimodal models are trained on massive amounts of data, including text, images, and audio. During this process, the model learns to recognize semantic relationships between input and output in different formats. For example, the model can relate an audio clip of a word “hello” and its text representation, or recognize the image, audio, and textual description of a thunderstorm as related aspects of the same event. This ability to understand the connection between different input and output formats allows the model to interpret the user’s input and respond accordingly.
By bridging the gap between AI and human-like understanding, multimodal models enable new possibilities for utilizing technology. These models allow machines to process information and respond to our needs in a more comprehensive and sophisticated manner.
Example Use Case 1: Business Insight
The rise of big data in the early 2000s revolutionized corporate decision-making, emphasizing the value of data and the necessity for accessing tools. The data allow businesses to make strategic decisions, informed by facts, metrics, and insights, a process known as data-driven decision-making. However, accessing these data requires significant technical expertise to translate everyday language into complex machine language queries. Once the outcome is obtained, it still often requires technical interpretation to translate it into business insight.

Business leaders face challenges daily and many decisions need to be made. Obtaining the right data to drive the decision is an important step that might take a lot of time, and, more often than not, the decision cannot wait. This is the way multimodal models enter the stage. By understanding and translating human language into machine language for data handling, the models enable the information in the data warehouses to be accessed with natural language. Furthermore, the retrieved data can be complex and difficult to understand. Frankly, most people won’t be able to understand that. Multimodal models can also present the data in simpler formats, such as charts or graphs, along with summaries that highlight key messages to the user and guide the decision-making process in the right direction.
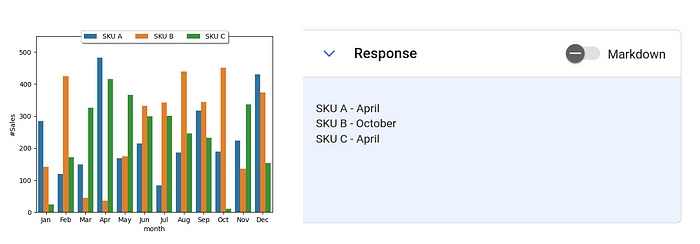
Imagine an executive trying to understand the sales performance of 3 SKUs last year, a multimodal model could allow the executive to simply ask “Which month has the highest sales for SKU A, B, and C?“ The model would then present the findings: SKU A performs best in April, SKU B in October, and SKU C in April. This provides a prompt response that is also simple and easy to understand.
Example Use Case 2: Human-like Response to an Image
Advanced LLMs, such as GPT4, have demonstrated their capability to make decisions and respond conversationally, much like humans [10] [11] [12]. Leveraging this capability, LLMs have been used as assistants for various tasks, such as drafting formal articles, summarizing lengthy and tedious paragraphs into short and concise sentences, and analyzing sentiment and intent from texts. LLM-powered assistants excel at understanding user instructions and generating responses that mimic human communication.
Multimodality takes LLM capabilities to emulate human response even further, enabling them to understand both text and visual clues. The assistant can now analyze images and provide feedback to the user based on the user’s instructions. Similar to drafting an article, users can ask for a draft for a webpage or advertisement banner. LLMs can process images and generate summaries that describe the image as a short paragraph, including extracting information from the image. They can also categorize images due to their ability to understand visual clues.

While these capabilities might not seem like a groundbreaking advancement in computer vision AI, each of these tasks, and others, requires specialized AIs. Multimodality empowers a single, sophisticated AI to handle various tasks based on user instructions, effectively replacing an army of assistants with a single intelligent one to help with many general day-to-day activities.
Multimodality goes beyond text and images, with audio and video rapidly becoming the next focus of the development of multimodality models. Researchers and developers around the world, from academia to the private sector, have been developing and improving these AIs to enhance their capability constantly. For example, Nvidia’s Instant NeRF can generate realistic video sequences from a few images, creating 3D object projections [13]. Similarly, Google Research’s VideoPoet can create a short video from a single image [14]. These advancements signal the arrival of a new wave of AIs, bringing with it exciting possibilities and imaginative applications.
References
[1] OpenAI, Introducing ChatGPT (2022) URL: https://openai.com/index/chatgpt/ Retrieved: May 24th, 2024
[2] S. Pichai and D. Hassabis, Introducing Gemini: Our Largest and Most Capable AI Model (2023) URL: https://blog.google/technology/ai/google-gemini-ai/ Retrieved: May 24th, 2024
[3] Gemini Team, Gemini: A Family of Highly Capable Multimodal Models (2024) arXiv: 2312.11805
[4] Gemini Team, Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context (2024) arXiv: 2403.05530
[5] H. Touvron et al., LLaMA: Open and Efficient Foundation language Models (2023) arXiv: 2302.13971
[6] Meta Introducing Meta Llama3: The Most Capable Openly Available LLM to Date (2024) URL: https://ai.meta.com/blog/meta-llama-3/ Retrieved: May 24th, 2024
[7] A. Q. Jiang et al., Mixtral of Experts (2024) arXiv: 2401.04088
[8] A. Kirillov et al., Segment Anything (2023) arXiv: 2304.02643
[9] A. Radford et al., Learning Transferable Visual Models From Natural Language Supervision (2021) arXiv: 2103.00020
[10] J. S. Park et al., Generative Agents: Interactive Simulcra of Human Behavior (2023) arXiv: 2304.03442
[11] G. Simmons and C. Hare, Large Language Models as Sub-population Representative Models: A Review (2023) arXiv: 2310.17888
[12] C. R. Jones and B. K. Bergen, People cannot distinguish GPT-4 from a human in a Turing test (2024) arXiv: 2405.08007.
[13] J. Stephens, Getting Started with NVIDIA Instant NeRFs https://developer.nvidia.com/blog/getting-started-with-nvidia-instant-nerfs/
[14] D.Kondratyuk et al., VideoPoet, A Large language Model for Zero-shot Video Generation https://sites.research.google/videopoet/
Originally published at https://www.sertiscorp.com/sertis-ai-research
