
1. What is object tracking?
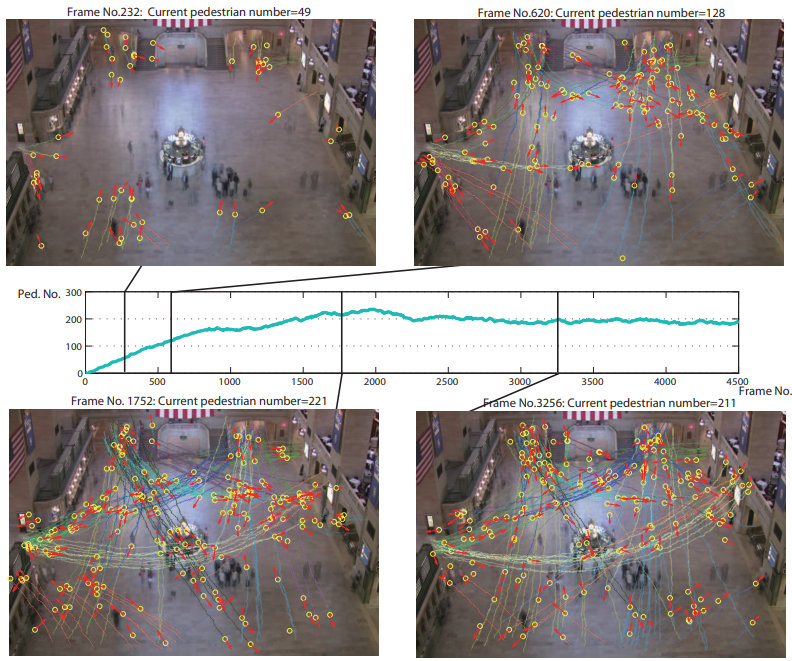
Object tracking is a computer vision technology serving as a core module in many video analytics systems. It aims to locate objects of interested classes, such as people or vehicles, in an input video sequence and generate their trajectories. Consequently, object tracking needs the capability of associating detected objects between frames of a video. This task is more challenging than object detection, which aims only at localizing objects of interest in an image and generating a list of bounding boxes as output. As shown in Fig. 1, an object tracking system detects two persons in a frame of video and generates bounding boxes to enclose the detected person. Each bounding box is also assigned with an identification (ID) number, i.e., in the example, 1 for the left person and 2 for the right person. In the following frames, the object tracking system still detects the two persons and assigns the same ID to them, showing its capability to correctly associate persons between frames. Figure 2 illustrates trajectories, i.e., the results of object tracking, in a more complicated scene.

1.1 Types of object tracking
Object tracking can be divided into types based on different properties such as the number of target objects, the number of camera viewpoints, or the way to process the data.
Single-object tracking (SOT) vs. multi-object tracking (MOT)
Based on the number of target objects to track, object tracking research can be divided into two types: single-object tracking (SOT) and multi-object tracking (MOT).
SOT aims at locating and tracking one target object throughout an input video, while all other objects are ignored (Fig. 3). In SOT research, an example image of a target object is usually given as input, apart from the video. Otherwise, the first frame of the input video annotated with a bounding box enclosing the target object can be used as a target image. This target image is used as a template in SOT when searching for this object in the other frames of the video. Correlation filtering or Siamese neural networks can be used to search for the target object in the subsequent video frames. Usually, the target object can be of any class which need not be known object classes used during training. In other words, SOT works with unseen categories of objects.
On the other hand, MOT aims at locating and tracking all objects of interested classes that appear in the input video (Fig. 4). Different from SOT, MOT does not require a process to specify the target object at the beginning of the video or any additional target images. However, the classes of objects need to be known during the training process. An MOT tracker automatically determines the number of objects in each frame of the video and associates them with existing tracks if they belong to the same object; otherwise, new tracks are created for the remaining objects that could not be matched with any of the existing tracks. Deep learning-based approaches are currently the mainstream in this research.


Single-camera tracking (SCT) vs. multi-camera tracking (MCT)
Object tracking can be performed on a stream of video obtained from a single camera, i.e., single-camera tracking or SCT, or on video streams from a network of cameras, i.e., multi-camera tracking (MCT).
In SCT, a video stream obtained from a single camera is processed (Fig. 4). The viewpoint in the video stream may be fixed in the case of stationary cameras or varied in the case of moving cameras. In the former cases, camera motion compensation is not necessary but a motion model predicting how a target object is moving in the upcoming frames is usually required. In the latter cases, both camera motion compensation and object motion model are required. Many deep learning-based object tracking researches focus on improving the accuracy and efficiency of SCT.
In contrast, MCT takes several videos captured by a number of cameras as input and tries to track objects appearing in each video and associate them across videos (Fig. 5). Therefore, MCT is more challenging. Generally, an MCT system exploits an SCT method to track objects in every single stream of video; however, MCT needs one more step to match local tracks obtained from each video with those from each other video. MCT settings can be divided into overlapping fields-of-view (FOVs) and non-overlapping FOVs. Overlapping FOV settings are normally exploited in a small observation area, for example, in a room. In this setting, an object can be simultaneously seen from two or more cameras. Therefore, the local track association step can leverage extra information such as ground-plane coordinates or moving patterns of objects to compute the similarity among local tracks from different cameras. In non-overlapping FOV settings, this extra information cannot be obtained; consequently, it usually requires an additional module called re-identification (ReID) to compute the similarity among local tracks from different cameras. A ReID module takes an image or video of a target as a query and compares it with those in a gallery. The similarity scores between the query and gallery items are then computed and ranked. In MCT, a local track from one camera is matched with other local tracks from different cameras using this ReID module. If the similarity score between two local tracks from two different cameras is sufficiently large, the two local tracks would be grouped into the same global track.

Online tracking vs. offline tracking
Object tracking can be performed in an online or offline manner, regardless of being SOT, MOT, SCT, or MCT.
In online tracking, the output prediction needs to be made based only upon the current frame and past frames. In other words, future information from the subsequent frames is not allowed in online tracking. This constraint makes it more challenging.
In offline tracking, it is allowed to use a batch of frames as input, and therefore, future information from the subsequent frames can be used to predict the result of a current frame. Therefore offline tracking is usually superior to online tracking in terms of accuracy. However, offline tracking is not practical in some applications, especially when real-time processing is required.
Note that this blog post focuses on notable online MOT research in SCT settings.
2. How multi-object tracking (MOT) works?
This section reviews notable state-of-the-art single-camera multi-object tracking systems which can be divided into two main approaches: 1) tracking-by-detection and 2) joint-detection-and-tracking.
Tracking-by-detection approach firstly leverages an object detector to locate objects in each frame of the input video. Then it associates these detected objects between frames into tracklets based on their similarity scores. Notable methods in this approach include SORT [6], DeepSORT [7], FairMOT [8], ByteTrack [9], and StrongSORT [10].
Joint-detection-and-tracking approach simultaneously solves detection and tracking tasks in a single framework. This joint framework allows detection performance to be boosted by tracking information (detection-by-tracking). It is a recent trend in MOT research. Notable methods include Tracktor [11], JDE [12], CenterTrack [13], and PermaTrack [14]. Recently, Transformer-based methods, such as TransTrack [15] or TrackFormer [16], have also been proposed.
The following subsections provide a review of notable methods of the two approaches.
2.1 Tracking-by-detection methods
SORT
Bewly et al. [6] proposed a simple online and real-time tracking or SORT method that associates detected objects based on an intersection-over-union (IOU) distance.
SORT adopts Faster Region-CNN (FrRCNN), a two-stage object detector, to locate objects in each video frame. Each detected object is represented by a state vector consisting of the center location, scale, and aspect ratio of its bounding box in the current frame t as well as its velocity and the rate of change in its scale. This state vector is approximated using a linear constant velocity model based on the information of the current frame t and the previous frame t−1.
Kalman filter is used as a motion model to predict the state of each object in the next frame t+1. Once detected objects in frame t+1 are obtained, each is compared with the predicted state of each existing object in frame t to compute their IOU distance. Object association is then performed frame-by-frame using the Hungarian algorithm, which aims to minimize the cost of the bipartite matching between newly detected objects in frame t+1 and the existing objects. A minimum IOU threshold is also used to filter out poor matches. If a detection box is associated with an existing object, its state is then updated using Kalman filter.
DeepSORT
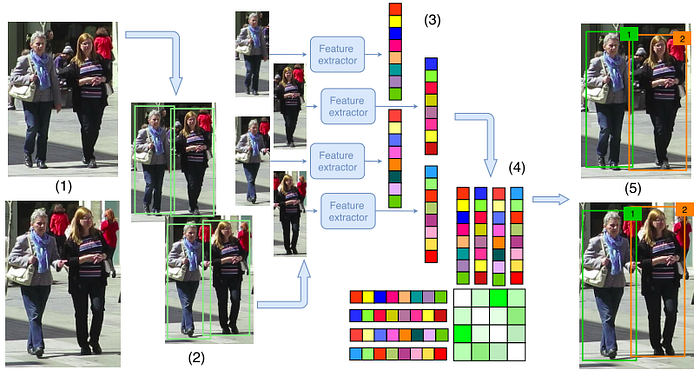
Wojke et al. [7] proposed an improved version of SORT [6] by leveraging an appearance model. The appearance model is trained to construct a deep association metric on a large-scale person ReID dataset. This model takes a cropped image of a detected person as input and converts it into an embedding vector representing distinguishing features to identify persons.
Different from SORT which uses only the IOU-based distance for object association, DeepSORT combines it with a visual appearance distance obtained from the ReID model. In particular, when a detection i is compared with an existing tracklet j, their visual appearance features, i.e., the embeddings, are compared to obtain their cosine distance. A weighted sum between the IOU distance and the cosine distance is then computed and used as the cost for object association.
Another difference between SORT and DeepSORT is that DeepSORT performs a cascade matching, in which tracklets with a smaller age are compared and associated with new detections before those with a larger age. The term age in this context refers to the number of consecutive frames that a tracklet has not been matched with any new detection. If it is matched in the current frame, the age is reset to zero; otherwise, it is increased by one. The method, therefore, gives priority to objects that have been seen more recently.
After these age-based cascade matching, the original SORT association, which is based solely on the IOU distance, is applied as the final step for the unmatched tracklets and detections. This final step is done to take into account the case of sudden changes in visual appearance, which might occur from time to time.
FairMOT
Zhang et al. [8] proposed FairMOT to address unfairness between detection and ReID branch. They propose two homogeneous branches, detection and ReID branches, to predict pixel-wise objectness scores and ReID features, respectively. FairMOT obtained high levels of detection and tracking accuracy and achieved state-of-the-art performance in MOT15 [17], MOT16, MOT17 [18], and MOT20 [19].
They adopt DLA-34 which is ResNet-34 with Deep Layer Aggregation (DLA) and convolution layers in all up-sampling modules are replaced by deformable convolution. For the detection branch, there are three parallel heads appended to DLA-34 to estimate heatmaps, object center offsets, and bounding box sizes. The heatmap head estimates the object’s center, the object center offsets head aims to localize object centers more precisely and the bounding box head is responsible for estimating the height and width of objects. In the ReID branch, they applied a convolution layer with 128 kernels on top of backbone features to extract ReID features for each location.
ByteTrack
Zhang et al. [9] proposed a method named ByteTrack which achieved state-of-the-art performance on MOT17 [18] and MOT20 datasets [19].
ByteTrack exploits YOLOX, a recent object detector in the YOLO series, to detect persons. Their YOLOX models were not only trained on the MOT17 [18] or MOT20 [19] training sets but also on large-scale person datasets including CrowdHuman [20], CityPerson [21], and ETHZ [22] to make their detectors to be able to detect occluded persons.
Another key contribution of this research is that it proposes a simple but effective object association algorithm called BYTE that aims to associate every detection box. Similar to SORT, the BYTE algorithm requires a motion model, which is a Kalman filter, to predict the location of existing tracklets in the next frame and it uses IOU-based distance for object association. However, the BYTE algorithm gives priority to detection boxes with high confidence scores. These detection boxes are first associated with existing tracklets using the Hungarian algorithm. The remaining detection boxes with lower confidence are associated later on, instead of being thrown away. This simple but effective strategy allows ByteTrack to associate occluded objects, which normally have lower confidence, to boost up the recall while maintaining the association precision.
ByteTrack surprisingly achieved state-of-the-art performance without the use of any appearance model. The reason for not using any appearance model is that it aims at associating every detection box, including those with low confidence which are usually corrupted by severe occlusion or motion blur, resulting in non-reliable visual appearance features.
StrongSORT
Du et al. [10] revisited Deepsort [7] and improved it in various aspects, i.e., embedding and association. The new tracker was called StrongSORT. Moreover, they also proposed two lightweight plug-and-play post-processing algorithms: an appearance-free link model (AFLink) and Gaussian-smoothed interpolation (GSI), to refine the tracking results. StrongSort with two post-processing algorithms can achieve state-of-the-art performance in terms of HOTA and IDF1 on MOT17 and MOT20 datasets
Compared to DeepSORT, StrongSort upgrades the embedding by replacing CNN with BoT with ResNeSt50 backbone and pre-trained on the DukeMTMCreID dataset to extract more discriminative features. In addition, they replaced the feature bank with an exponential moving average (EMA). For the motion branch, they adopt Enhanced Correlation Coefficient (ECC) for camera motion compensation and replace vanilla Kalman filter with NSA Kalman algorithm. Furthermore, during feature matching, they solve the assignment problem with both appearance and motion information instead of employing only the appearance feature distance. Lastly, they replace the matching cascade with a vanilla global linear assignment.
Besides upgrading from DeepSORT, they propose two post-processing algorithms, AFLink and GSI. AFLink predicts the connectivity between two tracklets by relying only on spatio-temporal information and GSI interpolates tracks with Gaussian process regression. StrongSORT with AFLink and GSI achieves state-of-the-art performance on MOT17 and MOT20 datasets. Moreover, AFLink and GSI can be also applied to other tracking algorithms and it improved the tracking performance.
2.2 Joint-detection-and-tracking methods
Tracktor
Bergmann et al. [11] proposed a tracking algorithm that converts an object detector to a multi-object tracker. This idea allows it to require no training or optimization on tracking-specific data.
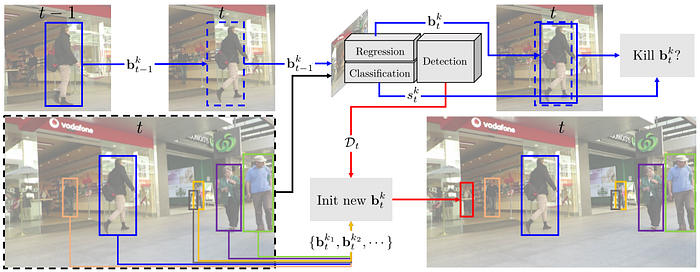
Tracktor exploits a regression head in an object detector, such as Faster RCNN, to perform tracking. In many state-of-the-art object detectors, this regression is used to refine the location of detected bounding boxes. As shown in Fig. 7, Tracktor simply places the bounding box of a target object in the previous frame t−1 on the current frame t to get feature maps. These feature maps are then fed into the regression head to refine the object’s location, which becomes the new location of that target object in the frame t. In this process, the object’s identity is automatically transferred from frame t−1 to frame t. However, it relies on an assumption that target objects move only slightly between frames, which may hold in case of high frame rate sequences.
To account for new target objects, Tracktor runs the detector on the current frame t and finds detection boxes that do not or slightly overlap with existing tracklets. These detection boxes are used to initialize new tracklets.
Two extensions to the original, vanilla Tracktor were also presented in the paper. The extended Tracktor is named Tracktor++. The first extension is the use of a motion model to handle the case of low frame rate sequences and the case of moving cameras. In which cases, a bounding box in frame t−1 might not overlap with its target object in frame t at all; consequently, the regression head does not have any clue to refine its location correctly. A motion model can help compensate for these errors, leading to more robust tracking. The second extension is to exploit a ReID model to verify if the target object in frame t−1 really matches its refined location in frame t. If not, this tracklet of the target object is deactivated.
Even though Tracktor++ does not require any tracking-specific training, it could establish itself as a strong baseline for single-camera person tracking during the time it was proposed.
JDE
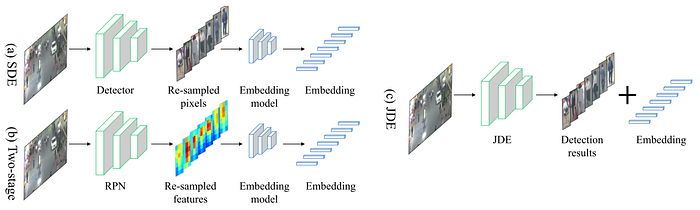
Wang et al. [12] proposed a real-time multi-object tracker that combines the detector and visual appearance model into a shared model. As shown in Fig. 8, some other trackers, especially the tracking-by-detection approach, exploit two separate models; one for object detection and another for generating visual appearance features, which are trained separately on different tasks. JDE, however, exploits a single-stage object detector that is jointly trained on detection and embedding generation tasks; consequently, it generates not only detected bounding boxes but also visual appearance features in one forward pass.
As shown in Fig. 9, JDE uses an architecture with Feature Pyramid Network (FPN) to handle objects of various scales. Apart from the box classification head and box regression head, JDE also has an embedding head to generate a dense embedding map representing the visual appearance features of detected objects. During the training, a cross-entropy loss is computed at the box classification head, a smooth-L1 loss at the box regression head, and a triplet loss at the embedding head. The first two losses are for training JDE to correctly locate and classify objects, while the third is to obtain features to distinguish intra-class objects. These losses are then fused together and used to guide the optimization process.

During the association step, JDE computes the motion affinity and appearance affinity matrices between all detections and all existing tracklets. These two matrices are combined to compute a cost matrix. Then Hungarian algorithm is applied once for each frame.
CenterTrack
Zhou et al. [13] proposed a simple and fast multi-object tracker named CenterTrack that is based on an object detector called CenterNet [23].
Different from other detectors that predict the top-left position of bounding boxes together with the size, CenterNet predicts the bounding boxes’ center instead. CenterNet takes a frame of video as input and generates a low-resolution heatmap representing the chance to find an object’s center and a size map representing the width and height of an object at each location. Each local maximum on the heatmap, called peak, is considered the center of a detected object.
As shown in Fig. 10, Zhou et al. [13] modified the architecture of CenterNet by adding the previous frame (three channels) and its heatmap (one channel) as additional input apart from the current frame. The additional inputs allow CenterTrack to know where detected objects in the previous frame are. They also added another branch to predict objects’ displacement between the two frames (two channels) as output. The displacement is used to perform association. In particular, each detection in the current frame at position p is simply associated with the closest unmatched detection in the previous frame at the displacement-compensated location p- d_p, where d_p is the predicted displacement of the predicted object at p.

CenterTrack does not require any video annotation to train it; however, it can be trained on a set of static images with detection ground truth. Given an image and its detection ground truth, the ground truth heatmap is generated by placing a normal distribution at the location of each object. The image is then randomly scaled and shifted to generate a simulated previous frame, in which its detection ground truth can be computed from the scaling and shifting factors. Once the objects’ locations in the current and simulated previous frame are known, the displacement can be obtained. These ground truths are then used to train CenterTrack with a pair of images as input. Due to the close similarity in the architecture, the weights of a pre-trained CenterNet can be exploited to initialize the corresponding weights in CenterTrack, while the other additional weights are randomly initialized. This training strategy allows CenterTrack to be jointly trained on detection and tracking tasks on a large-scale, static image dataset such as CrowdHuman dataset.
PermaTrack
Tokmakov et al. [14] proposed to leverage object permanence in their end-to-end multi-object tracker. When a target object, for example, a person, becomes invisible in a frame, the target may actually stay in the frame but fully occluded by some other objects and its location can be approximated. PermaTrack keeps track of the location of these invisible objects and once they appear visible again, they can be associated using their latest position during the invisible period.

PermaTrack is built based on the architecture of CenterTrack. A convolutional gated recurrent unit (ConvGRU) is inserted into the model as shown in Fig. 11 to convert a frame-by-frame feature map Fᵗ into a state matrix Mᵗ. This state matrix represents the entire history of previously seen objects. Predictions, i.e., heatmap, size map, displacement map, and additional visibility map introduced in PermaTrack, are made from this state matrix instead of the frame-by-frame feature map. The visibility map, generated by an additional visibility head, is binary, i.e., taking the value of either 0 or 1. Although PermaTrack is capable of keeping track of all objects disregarding their visibility, only visible objects are reported as the output to avoid being penalized during the performance evaluation since most real-world datasets do not provide annotation of invisible objects.
The lack of invisible object annotation also causes difficulty in training such a model since there is no supervised signal to tune the visibility head. Tokmakov et al. [14] solved this problem by using a tool, called ParallelDomain (PD), to generate a synthetic dataset in which the accurate ground truths of invisible objects are easily obtained. However, training a model purely on synthetic data could lead to poor performance on real-world data. Therefore, they jointly trained their model on synthetic data and real-world data. For the real-world data, due to the lack of invisible objects’ annotation, they trained the model with sequences of length two only, while for the synthetic data in which all ground truths are available, longer sequences can be used.
TransTrack
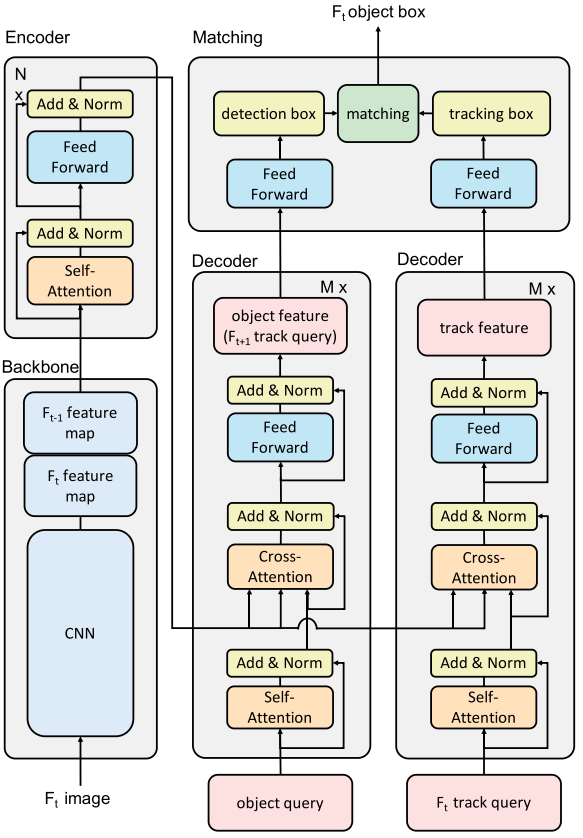
Sun et al. [15] proposed a Transformer-based model [24] for multi-object tracking named TransTrack. The architecture of TransTrack, which is extended from Detection Transformer (DETR) [25], is shown in Fig. 12. Firstly, a video frame is fed into a CNN backbone to compute a feature map. Secondly, the feature maps of the current frame t and the previous frame t-1 are linearly projected and reshaped into a sequence of tokens. Next, this sequence is processed by a Transformer encoder [24] to produce as output another sequence, in which its feature representation has been enhanced. In DETR, given a set of learnable object queries, this output sequence is then further processed by a Transformer decoder to produce object features. TransTrack, however, exploits another Transformer decoder that takes the object features from the previous frame as an additional input to predict the features of existing tracks. The object features and track features are then matched by a matching head to produce tracking results. Similar to other tracking methods, an unmatched track is set as inactive. A track is killed if it is inactive for a number of consecutive frames.
TrackFormer
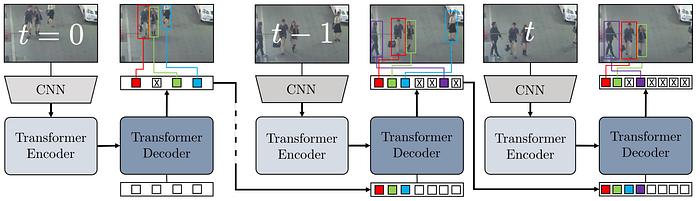
Meinhardt et al. [16] proposed TrackFormer, which is a multi-object tracking method that is similar to TransTrack but exploits only one Transformer decoder. As shown in Fig. 13, TrackFormer processes a video sequence frame-by-frame using its CNN backbone, followed by a Transformer encoder, and a Transformer decoder. In the first frame, the Transformer decoder takes a set of learnable object queries (shown as white boxes) as an additional input, similar to DETR. The Transformer decoder then predicts a set of tracks. In the next frame, these tracks’ features are then reused as track queries (shown as colored boxes), which are then combined with some of the object queries to produce a joint set of the same size. This joint set replaces the set of object queries to enable the decoder to track existing objects (using the track queries) as well as to detect new objects (using the remaining object queries). This process is then repeated to perform tracking for the whole video sequence. Both TransTrack and TrackFormer achieved state-of-art performance during the time they were published, showing the feasibility of using a Transformer module to solve tracking problems.
3. Applications of object tracking
Object tracking is a core module in video analytics systems which have been exploited in various fields. This section briefly introduces applications of object tracking technology.
Smart video surveillance
Using humans to continuously monitor CCTV cameras, especially in the case of a large network of cameras, is laborious and prone to mistakes. However, with people detection and tracking technology, video surveillance systems could be smarter, easier to manage, and require less or even no human labor. Real-time tracking of people on CCTV cameras allows us to generate the trajectory path of each tracked person. Therefore, it is easier to see from which direction a person came and in which direction the person is heading. With this capability, historical tracking for case investigation would be more convenient. People counting, in a specific zone or line counting, could also be done with tracking technology as well. This enables a real-time estimation of people in a motoring area. Social distancing violation detection could also be done automatically with people detection and tracking technology. It is also possible to use people tracking technology to alert security staff when someone is entering a prohibited zone or even to detect actions such as fighting, falling, or suspicious behaviors. People tracking also enables easy-to-understand visualization such as trajectory paths showing the movement direction of each person or heatmap showing which monitoring areas are more crowded.
Traffic monitoring
The capability of vehicle tracking is essential in CCTV-based traffic monitoring and management systems. Vehicle tracking estimates the location of each vehicle in each video frame, enabling us to easily compute vehicle velocity and traffic density. This information is crucial in traffic monitoring and management. For example, traffic lights could be optimized using AI given real-time traffic information. In addition, traffic rule violations, such as speed limit violations or lane changing in a prohibited area, could be automatically detected using vehicle tracking technology. Together with license plate recognition technology, these violations could be automatically recorded into a database system, reducing the manpower of traffic police.
Autonomous car
Autonomous vehicles, or self-driving vehicles, are being researched and developed by several companies. Obstacle avoidance is a crucial function of autonomous vehicles to ensure driving safety. There are various kinds of obstacles along the roads, for example, other vehicles, pedestrians, animals, construction barriers, and many more. An autonomous vehicle can exploit various kinds of sensors, such as LIDAR, RADAR, and vision sensors to avoid static obstacles such as construction barriers. However, to avoid collision with moving objects, tracking technology is required to obtain objects’ trajectories and predict their future movements. This information is essential for autonomous vehicles to perform path planning and control the movement direction and speed.
Customer behavior analysis
People tracking has also been applied in retail businesses to analyze customer behavior. Great customer experience would increase the chance that the customers will come back to the shop again, and a smart CCTV system with people tracking technology can provide valuable information on how to improve the shop services. Customers’ journeys, from entry to checkout, can be tracked with anonymous IDs using CCTVs installed inside a shop. The dwell time a customer spends in front of each shelf can tell the retailer about the customer’s interests. If a customer spends more time at a particular shelf, the customer is probably interested in some products on that shelf and might need some assistance. Using this information, the retailer can send some staff to interact with the customer right away. Similarly, when the smart CCTV system detects long queues at checkouts, it can alert the retailer to assign more staff to the checkouts immediately to improve the customer experience. Moreover, the retailer may analyze the customers’ journey during the whole day to see which shelves are or are not attractive based on the time customers spend at each shelf. This information can help retailers improve their shelf decoration and management.
Sports analytics
Sports analytics is crucial for a sports team or individual players to improve their games. Coaches, players, and staff usually analyze their games as well as their competitor’s games to find team strategies and tactics to increase their win rate. Scouting new players to join a team also requires players’ statistics to help make decisions. However, an analysis of how the team and each player play during an entire game is difficult and laborious, and in fact, there are so many games and so many players to analyze. Tracking technology can help automate and empower sports analytics by tracing individual players from video footage and generating players’ statistics. Moreover, this can be done at scale; a number of games can be analyzed automatically by this kind of technology. Visualization could also be done to assist in tactics analysis; for example, to show possible ways a soccer player can pass the ball to nearby teammates, to identify blockers, and so on.
References
Written by: Sertis Vision Lab
Originally published at https://www.sertiscorp.com/
