LOTR: Face Landmark Localization Using Localization Transformer
This blog post is a technical summary on the peer-reviewed novel research LOTR: Face Landmark Localization Using Localization Transformer proposed by Watchareeruetai et al. [1] in affiliation with Sertis Vision Lab.

Introduction
Nowadays, face recognition systems are commonplace in our daily lives, with businesses willing to take advantage of their convenience and robustness. Over the past decade, face detection and facial landmark localization have become crucial in aiding the performance of face recognition systems. While face detection refers to accurately detecting faces in an image, facial landmark localization focuses on estimating the positions of predefined key points in a detected face. These key points represent the different attributes of a human face, e.g., the contours of the face, eyes, nose, mouth, or eyebrows [1]. In recent years, facial landmark localization has become an important area of research in computer vision. It has aided in solving several computer vision problems like face animation, 3D face reconstruction, synthesized face detection, emotion classification, and facial action unit detection. However, it is challenging due to its dependency on face pose, illumination, and occlusion [2].
With the research in Convolutional Neural Networks (CNNs) gaining significant traction since the early 2010s, researchers have utilized their ability to extract contextual information from an image. Thus, using different variants of CNNs as the backbone, two approaches for facial landmark localization have been widely adopted: coordinate regression and heatmap regression.
Coordinate regression methods entail adding a fully-connected layer at the end of a CNN backbone to predict each landmark’s coordinates. On the other hand, heatmap-based approaches predict spatial probability maps wherein each pixel is associated with the likelihood of the presence of a landmark location. Heatmap-based techniques better utilize spatial information than coordinate regression methods that suffer from spatial information loss due to the compression of feature maps before the fully-connected layers. Additionally, heatmap-based approaches lead to better convergence than coordinate regression techniques and have achieved state-of-the-art performance on multiple evaluation datasets. However, they rely on generating large heatmaps, increasing the post-processing complexity.
Although the coordinate regression technique may suffer from the issue of spatial information loss, they offer an end-to-end solution at a lower computational complexity than heatmap-based approaches. With this motivation, in their paper, LOTR: Face Landmark Localization Using Localization Transformer, Watchareeruetai et al. [1] investigate a coordinate regression approach for facial landmark localization by exploiting Transformers [3] to address the issue of spatial information loss. The goal is to reduce computational complexity by straying away from additional post-processing steps like heatmap-based methods, yielding a more efficient network.
Proposed methods
Watchareeruetai et al. [1] propose the following novel ideas:
- A Transformer-based landmark localization network named Localization Transformer (LOTR).
- A modified loss function, namely smooth-Wing loss, which addresses gradient discontinuity and training stability issues in an existing loss function called the Wing loss [4].
LOTR: Localization Transformer

As the LOTR is a coordinate regression approach that directly maps an input image into a set of predicted landmarks, it requires neither heatmap representation nor any post-processing step. Fig.1 illustrates an overview of the architecture of the proposed LOTR framework. An LOTR model consists of three main modules, which include 1) a visual backbone, 2) a Transformer network, and 3) a landmark prediction head. The visual backbone takes an RGB image as input to capture context and produce a feature map as output.
Watchareeruetai et al. [1] exploit a pre-trained CNN such as MobileNetV2 [5], ResNet50 [6], or HRNet [7] to compute a feature map. Since the resolution of the feature map generated from the CNN backbone might be very low, e.g., 6x6 pixels for a 192x192 input image, the resolution is optionally increased by using upsampling layers such as deconvolution.
A Transformer network [3] is then added to the framework to enrich the feature representations while maintaining the global information in the feature map. As shown in Fig.1, the Transformer module is composed of a Transformer encoder and a Transformer decoder. Since Transformers were designed to process sequential data [3], they convert the feature map F of shape WxHxC, obtained from the visual backbone, into a sequence of tokens X⁰ of shape WHxD. A 1x1 convolution layer is applied to reduce the channel dimension C of each pixel in F to a smaller dimension D ≤ C, followed by reshaping into a sequence of tokens.
The Transformer network consists of an encoder and a decoder. The encoder, a stack of L layers, receives this sequence of tokens, X⁰, as input. Each encoder layer consists of two sublayers: 1) Multi-Head Self Attention (MHSA) and 2) Piece-wise Feed-Forward Network (PFFN). Both these sublayers have residual connections and layer normalization applied to them.
The MHSA establishes the relationship between tokens in the input sequence by computing the attention by linearly projecting each token into query, key, and value vectors and subsequently using the query and key vectors to calculate the attention weight applied to the value vectors. Furthermore, the output from the MHSA sublayer (the same size as its input) is then fed into PFFN to transform the input sequence’s representation. Like DETR [8], 2D-positional encoding is added only to the query and key in each encoder layer. The output of the Transformer encoder is a transformed sequence Xᴸ of shape WHxD, the same dimension as its input.
Following this encoding operation, the output from the Transformer encoder is then fed into a Transformer decoder, i.e., a stack of L decoder layers. Each decoder layer consists of three sublayers: 1) MHSA, 2) Multi-Head Cross-Attention (MHCA), and 3) PFFN. The first and the third are similar to those of the encoder layers. However, the input to the decoder’s first sublayer is a sequence of landmark queries Y⁰ of shape NxD. The number of landmark queries equals N, the number of landmarks to predict. The second sublayer, i.e., MHCA, takes the output of the first sublayer (MHSA) and the output generated by the encoder, i.e., Xᴸ, as inputs and then computes the relationship between tokens in both sequences. The third sublayer, i.e., PFFN, then processes the output from the second sublayer. Like the Transformer encoder, all three of these sublayers have residual connections and layer normalization applied to them.
The Transformer decoder produces an output Yᴸ of shape NxD.
The landmark prediction head takes as input the sequence Yᴸ and outputs landmarks Z of shape Nx2, which stores the predicted coordinated (x,y) of the N landmarks. Watchareeruetai et al. [1] exploit a simple PFFN with two hidden layers with ReLU activation. However, the output layer, which consists of only two nodes, is without any activation function.
Smooth-Wing Loss
Watchareeruetai et al. [1] propose the smooth-Wing loss to train the LOTR models. The smooth-Wing loss function is a modification of the Wing loss [4]. The key idea in the Wing loss is to force the model to pay more attention to small errors to improve the accuracy of the predicted landmarks. Feng et al. [4] define the Wing loss as:
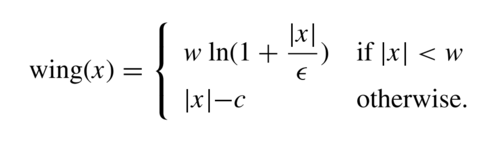
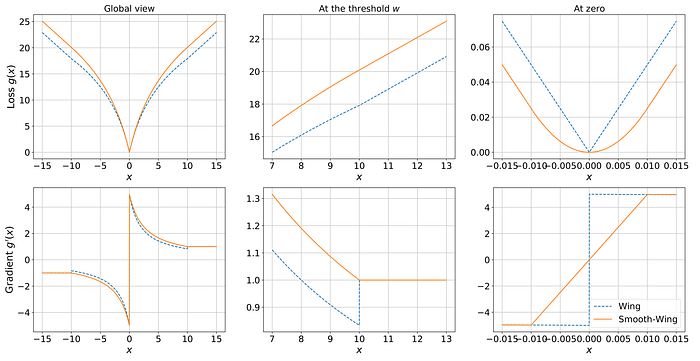
However, as shown in Fig. 2 the Wing loss produces the discontinuity of the gradient at the threshold w, and at zero error. This discontinuity can affect the convergence rate and the stability of training.
Watchareeruetai et al. [1] define the smooth-Wing loss as:
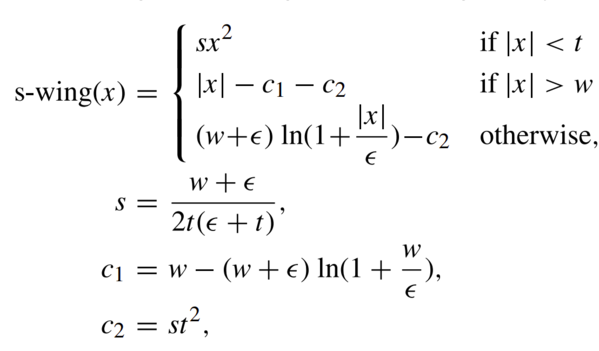
When the error is smaller than the inner threshold t, it behaves like L2 loss, allowing the gradient to be smooth at zero error; otherwise, it behaves like the Wing loss. The constants s, c₁, and c₂ are introduced to smoothen the loss at the inner threshold t as well as at the outer threshold w. As shown in Fig. 2 (bottom-right), the gradient of the smooth-Wing loss changes linearly when the absolute error |x| is smaller than the inner threshold t. Moreover, the gradient discontinuities at |x| = w are also eliminated, as shown in Fig. 2 (bottom-middle).
Experiments
Dataset & pre-processing
Watchareeruetai et al. [1] conducted experiments to measure the performance of the proposed LOTR models on two benchmark datasets: 1) the 106-point JD landmark dataset [10] and 2) the Wider Facial Landmarks in-the-Wild (WFLW) dataset [11].
Following Earp et al. [2], a ResNet50-based face detector, proposed by Deng et al. [12], was used in the pre-processing step. In particular, Watchareeruetai et al. [1] used the bounding box and a set of five simple landmarks (i.e., eye centers, nose tip, and mouth corners) obtained from the detector to crop and align the detected faces. Each input image was then resized to 192x192 pixels for the JD-landmark dataset and to 256x256 pixels for the WFLW dataset before feeding it to the LOTR models.
Models
Table 1 demonstrates the different configurations of LOTRs used in the experiments with the the 106-point JD landmark dataset [10] and 2) the Wider Facial Landmarks in-the-Wild (WFLW) dataset.
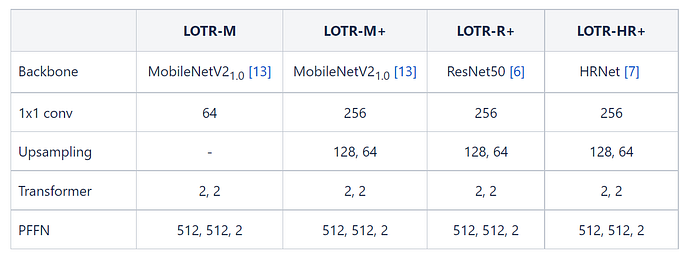
Unlike LOTR-M, where the number of feature channels was reduced to 64 after the 1x1 conv operation, the rest of the models had their feature channels reduced to 256. No upsampling operations were used for the LOTR-M model. In contrast, upsampling operations in the form of two subsequent deconvolution layers with 128 and 64 filters with filter size 4x4 were used for the LOTR-M+, LOTR-R+, and LOTR-HR+ models.
The Transformer encoders and decoders for all the models had two layers each. Watchareeruetai et al. [1] applied PFFNs consisting of two hidden layers with 512 nodes, with ReLU activation, followed by an output layer with two nodes to all the models.
Evaluation Metrics
Watchareeruetai et al. [1] used standard metrics such as the normalized mean error (NME), the failure rate, and the area under the curve (AUC) of the cumulative distribution to evaluate and compare different landmark localization algorithms to the LOTR models.
If the NME of a test image is above a threshold, it is considered a failure. The failure rate is, therefore, the rate of failure cases. Watchareeruetai et al. [1] set the threshold to 8% for the JD-landmark dataset and 10% for the WFLW dataset. The AUC is computed from the cumulative error distribution, representing the proportion of images with NME smaller than the threshold. Therefore, a larger AUC represents a more accurate algorithm.
Results
WFLW
On the WFLW dataset, Watchareeruetai et al. [1] compare the proposed LOTR-HR+ model with several state-of-the-art methods, including Look-at-Boundary (LAB) [11], Wing loss [4], adaptive Wing loss (AWing) [14], LUVLi [9], Gaussian vector (GV) [15], and Heatmap-In-Heatmap (HIH) [16].
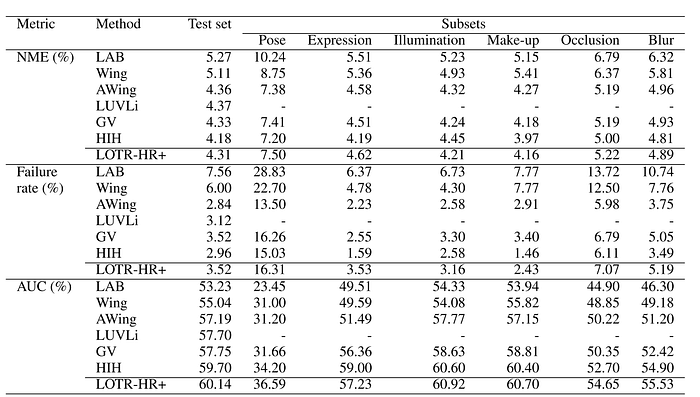
As shown in Table 2, the proposed LOTR-HR+ achieves an NME of 4.31%, clearly outperforming LAB, Wing, AWing, and LUVLi methods, and yields an AUC of 60.14%, surpassing all state-of-the-arts by a large margin (0.44–6.91 points).
While comparable with GV in terms of NME and failure rate, the LOTR model achieves a better AUC and does not require any post-processing step.
Although their proposed LOTR model does not surpass the performance of HIH in terms of NME and failure rate, it outperforms this state-of-the-art model on the AUC metric.

JD-landmark
Watchareeruetai et al. [1] evaluate the performance of the LOTR-M, LOTR-M+ and LOTR-R+ models on the the test set of the first Grand Challenge of the106-Point Facial Landmark Localization against the top two ranked algorithms submitted to the challenge [17] .
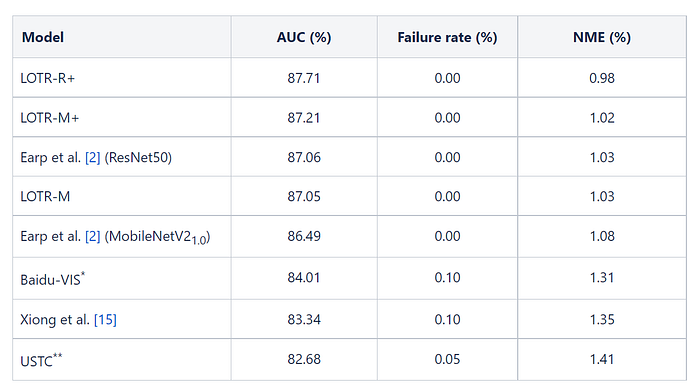
Table 3 shows that the proposed LOTR models, including the smallest model, i.e., LOTR-M, gain more than 3 points in the AUC in comparison to the top two ranked algorithms on the first challenge leaderboard. The table also compares LOTR models with two recent methods based on the heatmap regression, i.e., Earp et al. [2] and Xiong et al. [15].
All of the proposed LOTR models surpass the heatmap approach in Xiong et al. [15] by a significant amount of the AUC gain (3.7–4.5 points). In comparison with Earp et al. [2], the proposed LOTR models achieve better performance using the same backbone.
While the smallest model, i.e., LOTR-M, is comparable with the ResNet50 model by Earp et al. [2], the bigger models, i.e., LOTR-M+ and LOTR-R+, surpass it by an AUC gain of 0.15–0.65 points, showing the superiority of the approach proposed by Watchareeruetai et al. [1] over the rest.
Conclusion
The proposed LOTR models outperform other algorithms, including the two current heatmap-based methods on the JD-landmark challenge leaderboard, and are comparable with several state-of-the-art methods on the WFLW dataset. The results suggest that the Transformer-based direct coordinate regression is a promising approach for robust facial landmark localization.
Acknowledgements
AI researchers from Sertis Vision Lab, namely Ukrit Watchareeruetai, Benjaphan Sommana, Sanjana Jain, Ankush Ganguly, and Aubin Samacoits, collaboratively developed the novel LOTR framework for face landmark localization along with Quantitative researchers: Pavit Noinongyao and Samuel W. F. Earp from QIS Capital. Nakarin Sritrakool, who at the time of this research was affiliated with the Department of Mathematics and Computer Science, Faculty of Science, Chulalongkorn University, contributed immensely to this work during his internship at Sertis Vision Lab.
Read the full published article here.
References:
Written by: Sertis Vision Lab
Originally published at https://www.sertiscorp.com/
