
This blog-post series aims to explain the mechanism of Latent Diffusion Models (LDMs) [1], which are a type of latent text-to-image diffusion model. In addition, it also aims to provide a summary of its recent applications.
In Part I, we briefly introduced the mechanism of diffusion models and how they connect to variational autoencoders in generating samples matching the original data after a finite time. Additionally, we explained the mechanism of LDMs and how it addresses the problem of high computational complexity of traditional diffusion models.
This part focuses on some of the mainstream applications of LDMs and diffusion models, in general, mainly pertaining to computer vision problems and aims to briefly discuss the latest advancements in the field in the form of a series of text-to-image synthesis models named Stable Diffusion [2, 3].
1. Applications
Due to flexibility and strength, LDMs have recently been applied to tackle real-world challenging tasks. In this blog-post, we outline some of the pertinent computer vision tasks where LDMs and a few other diffusion models have proven to outperform state-of-the-art (SOTA) generative models.
1.1 In-painting
The main goal of image in-painting is to reconstruct regions of an image with new content either because parts of the image are are corrupted or to replace existing but undesired content within the image. Techniques such as RePaint [7] and Palette [8] leverage the mechanism of diffusion models operating directly in the pixel space of images propagating pixel values from the known regions of the image into the missing or corrupted regions, ensuring that the restored portions align seamlessly with the existing content. Recently, Rombach et al. [1] demonstrated new SOTA performance in image in-painting using LDMs.
In their work, Rombach et al. [1] compare the in-painting efficiency of different LDM-k models, where k represents the downsampling factor that the encoder uses to map an input image to its latent space. In particular, they compare LDM-1 (i.e. a pixel-based conditional DM) with VQ regularized LDM-4 both with and without any attention in the first stage. They observed an improvement in the FID scores by a factor of nearly 1.6x from LDM-1 to VQ-LDM-4 without attention. Furthermore, the VQ-LDM-4 without attention reduced GPU memory for decoding at high resolutions.
Based on these initial results, Rombach et al. [1] train their SOTA image in-painting LDM in which the second stage of training utilizes the latent space of the VQ regularized auto-encoder, with a downsampling factor of 4, and without attention. The UNet of this diffusion model uses additional attention layers on three levels of its feature hierarchy. These additional attention modules tend to cause a discrepancy in the quality of samples produced at resolutions 256x256 and 512x512. However, fine-tuning the model for half an epoch at resolution 512x512 allowed the model to adjust to the new feature statistics and set a new SOTA FID on image in-painting, the results of which are illustrated in Figure 1. For their experiments, Rombach et al. [1] use the Places dataset [6] for training and evaluation of their in-painting LDMs.

1.2 Super-resolution
In contrast to in-painting, image super-resolution aims to restore high-resolution images from low-resolution inputs. Super-Resolution via Repeated Refinement (SR3) [4] adopts diffusion models to make conditional image generation, and conducts image super resolution through a stochastic iterative denoising process. Cascaded Diffusion Models (CDM) [5] consists of cascaded multiple diffusion models which generate images of gradually increasing resolution. These methods directly conduct diffusion process on input images, resulting in large evaluation steps and high computational resources. LDMs [1] effectively address this high computational complexity of training and sampling processes of denoising diffusion models by moving the diffusion process into the latent space with pre-trained auto-encoders, however, without loss of quality as shown in Figure 2.
In the second training stage of their super-resolution LDM (LDM-SR), Rombach et al. [1] diretly condition on low-resolution images via concatenation with the inputs to the UNet. Through their experiments, Rombach et al. [1] demonstrate LDM-SR outperforms SR3 in in achieving a lower FID score. Figure 2 illustrates the comparative performance between LDM-SR, SR3 keeping bicubic interpolation as the baseline. Although, LDM-SR has advantages at rendering realistic textures, SR3 can synthesize more coherent fine structures.

1.3 Text-to-Image synthesis
The two-stage LDM training approach, proposed by Rombach et al. [1] utilizes a conditioning mechanism based on cross-attention in the second training stage. This facilitates multi-modal training useful for text-to-image synthesis, the idea of which is to generate realistic images for a variety of text prompts. For this purpose, Rombach et al. [1] train a 1.45B parameter KL-regularized LDM conditioned language prompts from LAION-400M [10] dataset. Furthermore, Rombach et al. [1] employ the BERT-tokenizer [11] and implement a transformer as the encoder which converts the input from the tokenized text-prompts modality into an intermediate representation that is then mapped to the layers of the UNet via multi-head cross-attention. This allows for learning a joint distribution over discretized image and text representations resulting in a powerful model, which generalizes well to complex, user-defined text prompts.
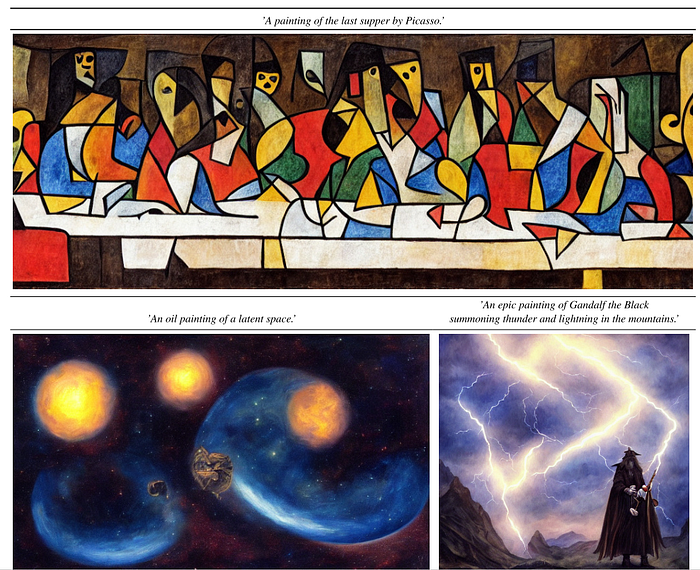
1.3.1 Stable Diffusion
Building on the work by Rombach et al. [1], Stability AI and Runway collaborated on releasing a series of text-to-image LDMs under the name of Stable Diffusion [2, 3]. These models were trained in 512x512 images from a subset of the LAION-5B [13] dataset and use a frozen CLIP ViT-L/14 [13] text encoder to condition the models on text prompts. For instance, their Stable Diffusion v1 model uses a 860M UNet and 123M text encoder, and is relatively lightweight and runs on a GPU with at least 10GB VRAM. With the release of these models, users can now generate photo-realistic images using any text input while cultivating autonomous freedom to produce incredible imagery, and empowering billions of people to create stunning art within seconds. A few examples of generative art using Stable Diffusion is illustrated in Figure 4.

1.4 Classification
Although generative models tackle the more challenging task of accurately modeling the underlying data distribution, they can create a more complete representation of the world that can be utilized for various downstream tasks. Similarly, in addition to exhibiting impressive compositional generalization abilities in the task of text-to-image synthesis, LDMs provide conditional density estimates, which are useful for tasks beyond image generation. In particular, the density estimates from large-scale text-to-image LDMs can be leveraged to perform zero-shot classification without any additional training [9]. Recently, Li et al. [9] proposed a zero-shot diffusion classifier which utilizes a text-to-image LDM trained on a filtered subset of the LAION-5B [23] dataset. Li et al [9] compare the performance of their zero-shot LDM classifier with two contrastive baselines, namely OpenCLIP ViT-H/14 [12] and CLIP ViT-L/14 [13] on several benchmark datasets. On Winoground [22], a popular benchmark for evaluating the visio-linguistic compositional reasoning abilities of vision-language models, the LDM classifier significantly outperforms the other two discriminative models as shown in Table 1.

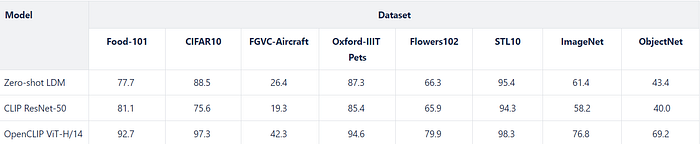
In terms of classification performance, Li et al. [9] compare the performance of their classifier against two zero-shot models, namely CLIP ResNet-50 [13] and OpenCLIP ViT-H/14 [12]. They evaluate the performance of their classifier across eight benchmark datasets : Food-101 [14] CIFAR-10 [15], FGVC-Aircraft [16], Oxford-IIIT Pets [17], Flowers102 [18], STL-10 [19], ImageNet [20], and ObjectNet [21]. As shown in Table 2, the proposed zero-shot LDM classifier outperforms CLIP ResNet-50 and is competitive with OpenCLIP ViT-H/14.
2. Summary
This series on LDMs aimed at summarizing the mechanism of diffusion models and cover the problem of high computational complexity of traditional diffusion models. Additionally, this series also discusses how the splitting the training stage into two phases enables LDMs to learn from the latent space of auto-encoders thereby reducing the computational complexity to enable diffusion model training on limited computational resources while retaining their quality and flexibility. Furthermore, we see how recent research has proven that various LDM variants have proven to be the new SOTA on several vision tasks such as classification, in-painting, image super-resolution and text-to-image synthesis.
References
[1] High-Resolution Image Synthesis with Latent Diffusion Models
[4] Image Super-Resolution via Iterative Refinement
[5] Cascaded Diffusion Models for High Fidelity Image Generation
[6] Places dataset
[7] RePaint: Inpainting using Denoising Diffusion Probabilistic Models
[8] Palette: Image-to-Image Diffusion Models
[9] Your Diffusion Model is Secretly a Zero-Shot Classifier
[10] LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs
[11] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[12] Reproducible scaling laws for contrastive language-image learning
[13] Learning Transferable Visual Models From Natural Language Supervision
[14] Food-101 — Mining Discriminative Components with Random Forests
[15] The CIFAR-10 dataset
[17] The Oxford-IIIT Pet Dataset
[18] 102 Category Flower Dataset
[19] STL-10 dataset
[20] ImageNet Large Scale Visual Recognition Challenge
[21] A large-scale bias-controlled dataset for pushing the limits of object recognition models
[22] Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
[23] LAION-5B: An open large-scale dataset for training next generation image-text models
