
Introduction
It’s hard to say when the journey of Natural Language Processing (NLP) began. According to the Wikipedia’s article ‘History of natural language processing’ [1], it may have started in the seventeenth century when Leibniz and Descartes attempted to understand the relationships between words in different languages or it may have been initiated by the work of Alan Turing, including his question “Can machines think? “ and his famous imitation game [2].
As we know, computer scientists are constantly pushing the boundaries of NLP, aiming to create machines that truly understand human language, from the development of basic rule-based chatbots such as Eliza in 1967, advancing to the invention of more sophisticated deep learning approaches [3]. Figure 1 illustrates a rough timeline of Large Language Models (LLMs). In 1967, the first chatbot, Eliza was created. It used pattern matching and keyword recognition to simulate human language understanding [3]. In 1997, the Long Short-Term Memory (LSTM) networks were invented [4]. LSTMs are a deep learning approach that considers the sequential nature of language and has the ability to remember or forget information to improve language understanding. Today, LSTMs remain a valuable tool and a good choice for tasks involving sequential data. The development continues, with the biggest breakthrough occurring in 2017, Google’s groundbreaking transformer architecture ushered in a new era of natural language processing and understanding [5].

Today, progress in LLMs is happening at lightning speed. High competition drives innovation, with new breakthroughs emerging daily. Figure 2 illustrates the ongoing development of LLMs in the modern world. As the figure shows, the era began with models like BERT, GPT-2, GPT-3, and PaLM. The new releases of LLM models have even higher performance and larger numbers of parameters. We can now confidently assert that these efforts have yielded significant accomplishments, evidenced by the capabilities demonstrated by models like Google’s Gemini or GPT-4.

Ready to get technical? This article explores a deep dive into transformers, the core technology behind cutting-edge language models, and examines the mechanism behind GPT. Let’s unlock the mysteries of how machines are learning to speak our language!
From Transformer to LLMs
LLMs represent a significant advancement in the field of natural language understanding, building upon the foundation of traditional tasks which are fundamentally sequence modeling problems. In written and spoken language, words are arranged in a specific order to convey meaning. This sequential structure is crucial for understanding the relationships between words and the overall context of a sentence or text. For example, in English, the word order is typically subject-verb-object in simple sentences, such as
“The cat (subject) chases (verb) the mouse (object).”
Changing the word order can alter the meaning of the sentence. In more complex sentences, the sequential nature of language becomes even more important for understanding the relationships between different parts of the sentence.
In sequence modeling, the goal is to understand and generate sequences of tokens (words, characters, etc.) in a coherent and meaningful way.
Here are some examples of NLP problems that can be considered as sequence modeling tasks:
- Machine Translation: In machine translation, the goal is to convert a sequence of words from one language into another language.
- Named Entity Recognition (NER): NER is the task of identifying and classifying named entities (such as person names, organization names, etc.) in a text.
- Part-of-Speech (POS) Tagging: POS tagging involves assigning a part-of-speech tag (such as noun, verb, adjective, etc.) to each word in a sentence.
- Text Generation: Text generation tasks involve generating sequences of text that are coherent and contextually relevant.
- Sentiment Analysis: Sentiment analysis involves determining the sentiment (positive, negative, neutral) of a piece of text.
In all of these cases, the fundamental task is to model the relationships between the elements in a sequence (words, characters, etc.) in order to understand the underlying structure and meaning of the text.
Before the era of the transformers, there were several state-of-the-art approaches that addressed this sequential behavior, such as recurrent neural networks (RNNs), long short-term memory (LSTM), and gated recurrent units (GRUs). These techniques lead to performance improvement; however, some challenges remained, such as:
- Difficult parallel computing: Traditional sequence transduction models based on RNNs process input sequences sequentially, limiting parallelization and leading to long training times.
- Information loss for long sequences: RNNs, which are commonly used in sequence transduction tasks, struggle to capture long-range dependencies in sequences due to the vanishing gradient problem. This is because, by their mechanism, they tend to assign lower relevance to words that are farther away in longer sentences.
The transformers use attention mechanisms that allow it to capture relationships between words in a sequence parallelly, significantly reducing computation time. The attention mechanism also allows the model to attend to all positions in the input sequence, enabling it to capture long-term dependencies more effectively.
Transformers
The transformers are a class of neural network architecture introduced in the paper ‘Attention is All You Need’ [7]. As the name suggests, the transformers are a model that relies entirely on attention mechanisms to compute representations of its input and output without using sequence-aligned RNNs or convolution.
What is Attention ?
Attention, as the name suggests, tells the model which parts of the information to focus on to create a contextual representation of language. The attention mechanism is a function that calculates the importance of each piece of information (token in the context of language models). It takes two inputs: a query (question) and a list of information represented as key-value pairs. The output is a weighted combination of these information elements, where the weight assigned to each piece reflects its relevance to the query. This relevance is determined by a compatibility function that compares the query to each information item.
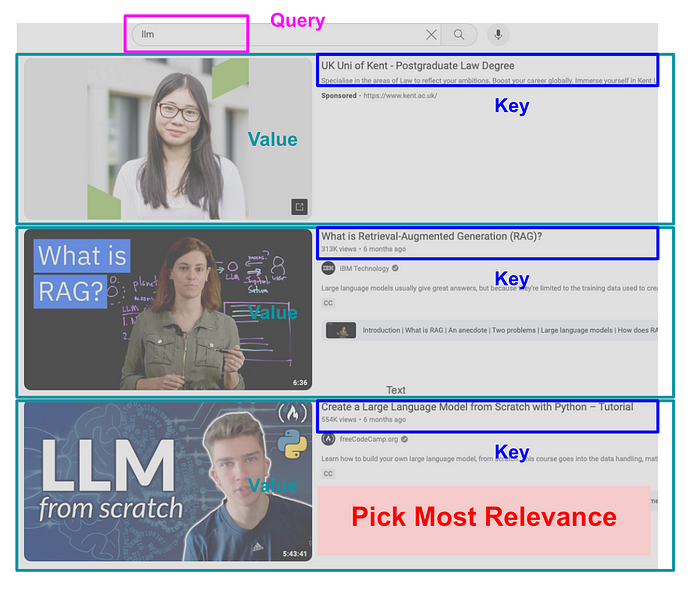
Here’s an analogy to help understand how it works: imagine using a search engine. Let’s say you want to find LLM content on YouTube. First, you type in your query, which in this case is “LLM”. YouTube then suggests videos that might be relevant to your keywords. These videos have titles and content. We can think of the titles as keys and the corresponding content as values. Finally, you choose the video title (key) that seems most relevant to your query based on the relationship between your search term and the title and content of each video. The one with the highest relevance is most likely the one you’ll pick. In this case, you might select the third video shown in Figure 3.
There are multiple types of attention mechanisms, each designed for specific purposes. For example, the paper introduced encoder-decoder transformers (Figure 4), which are designed to address sequence-to-sequence tasks, such as machine translation. This kind of transformers utilize three types of attention: self-attention, encoder-decoder attention, and masked self-attention. This article won’t explain the designs of each type of attention. For more details, please refer to the original paper [7].
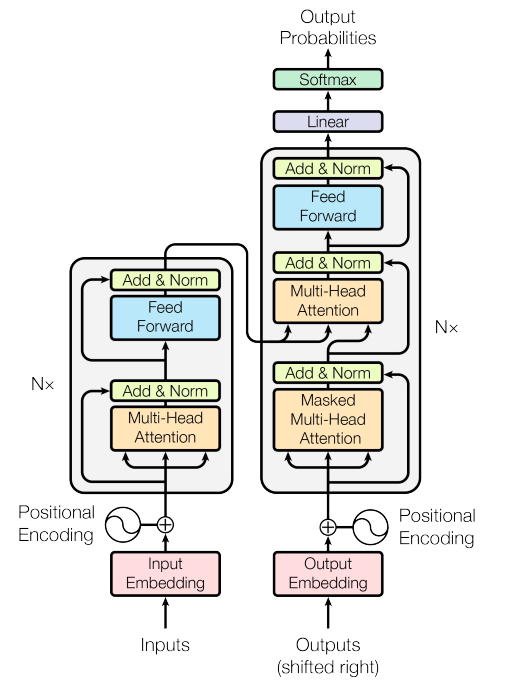
Encoder-Decoder Transformer
The encoder-decoder transformers consist of 2 major parts: encoder block (left-hand side of the diagram) and decoder block (right-hand side of the diagram). The encoder block processes the input sequence and extracts its contextualized representations using self-attention. The decoder block, on the other hand, is responsible for generating the output sequence based on the contextualized representations learned by the encoder, using encoder-decoder attention. Additionally, the decoder processes the output sequence autoregressively using another type of attention called masked self-attention, generating one token at a time while attending to the previously generated tokens and the encoder’s output.
The design of transformer architecture can vary based on the specific application. For example, BERT (Bidirectional Encoder Representations from Transformers) consists solely of the encoder component of the transformers. The encoder processes input sequences bidirectionally, allowing it to capture context from both left and right directions. On the other hand, GPT is designed to utilize only the decoder component of the transformers to generate output sequences autoregressively, meaning it predicts one token at a time based on previously generated tokens.
LLMs
A primary challenge for NLP tasks remains the shortage of labeled data, despite the availability of many open-source text datasets. Traditionally, most solutions rely on supervised learning approaches that require this manually labeled data. However, OpenAI introduced a semi-supervised approach in their work titled “Improving Language Understanding by Generative Pre-Training” [8]. This approach leverages a massive amount of unlabeled data to build an unsupervised pre-trained model, which is then fine-tuned for specific tasks using supervised learning with labeled data.
Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks. (Radford et al., 2018)
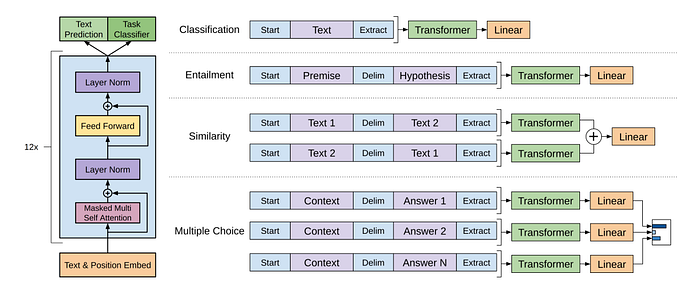
Unsupervised pre-training
First, the language model leverages large-scale unlabeled data to learn general language representations using the transformer decoder, as shown in (as shown in Figure 5, left). During this process, the model is trained to predict the next token in a sequence of text given the preceding tokens. During training, the model is fed sequences of tokens, and the parameters of the model are updated to maximize the likelihood of predicting the correct next token in each sequence.
Supervised fine-tuning
These pre-trained model parameters can be adapted for various downstream tasks like text classification or question answering. Here, the model is fine-tuned on a labeled dataset (denoted as input set X and output y). The inputs are fed through the pre-trained model from the first step. The model is then further trained to find the optimal parameters to accurately predict the desired output (y).
The architecture of fine-tuning and the format of input labeled data can vary depending on the task (as shown in Figure 5, right). For instance, text classification tasks might require a different fine-tuning architecture compared to question answering tasks, due to the differing nature of the outputs predicted.
Here are some examples of fine-tuning architectures and the corresponding formats for input labeled data.
Example 1: Question Answering
The general format of input and output is:
Question: What is the capital city of Australia?
Answer: The capital city of Australia is Canberra.
Since the pre-trained model is trained to predict the next token of a sequence of tokens, the form of the data needs to be transformed to the required representation, such as:
<Question> What is the capital city of Australia? <Answer> The capital city of Australia is Canberra <End>.
Example 2 : Semantic Textual Similarity (STS)
The goal is to measure the degree of semantic similarity or relatedness between pairs of sentences. For this task, there are two given sentences:
Sentence 1: The sun sinks, painting the sky orange.
Sentence 2: The setting sun tints the sky with orange hues.
For this kind of task, the comparison of two sentences does not depend on a specific order of sentences. Hence, the data can be modified as:
<Start> The sun sinks, painting the sky orange. <|> The setting sun tints the sky with orange hues. <End>
<Start> The setting sun tints the sky with orange hues. <|> The sun sinks, painting the sky orange. <End>
Each sequence of text is fed to the model independently and produces two final transformer block activations. Then, the components are concatenated before being fed into the final linear layer.
At this stage, LLMs possess both universal representation and the ability to adapt to downstream tasks. However, creating chatbots like ChatGPT or Gemini requires further refinement through techniques such as reinforcement learning, human feedback integration, and intensive training on instruction fine-tuning. This fine-tuning involves presenting the model with various scenarios and adjusting its responses based on how well they align with desired conversational outcomes, such as coherence, relevance, and appropriateness.
Next Steps in LLMs
LLMs stand as an achievement to the long journey of natural language processing and understanding research. Their ability to generate human-like text empowers them to act as useful personal assistants, helping us in writing, answering questions, and even drafting creative ideas. Furthermore, integration with external tools like RAG and LangChain unlocks a next level of efficiency, allowing them to tap into external knowledge sources and leverage tools like SQL, search engines, and calculators. The rise of Multimodal Generative AI, such as Gemini and GPT-4, pushes the boundaries even further. These models not only generate text but also process and create diverse data formats, including images and speech. While the current capabilities of Generative AI are impressive, the potential for even greater development is undeniable. However, responsible development is significantly important to address concerns surrounding bias, safety, and transparency. By encouraging open dialogue and prioritizing responsible practices, we can anticipate LLMs become a powerful force for positive change in the world.
References
[1] History of natural language processing
[2] https://redirect.cs.umbc.edu/courses/471/papers/turing.pdf
[3] ELIZA
[4] https://deeplearning.cs.cmu.edu/F23/document/readings/LSTM.pdf
[5] BERT: Pre-training of Deep Bidirectional Transformers for Language…
[6] The Rise of Generative AI Large Language Models (LLMs) like ChatGPT — Information is Beautiful
[8] Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
Written by: Sertis Vision Lab
Originally published at https://www.sertiscorp.com/sertis-ai-research
