From Surveillance to Safety: How Sertis Vision Lab is Enhancing Fire & Smoke Alarms with CCTV Feed

Introduction
Fire and smoke detection in video streams form a valuable feature in surveillance systems, as their utilization can prevent hazardous situations. There are a number of conventional and cutting-edge fire and smoke detection techniques that have been proposed to reduce damage brought on by fire disasters. Sensor-based and vision-based smoke detection systems have garnered a lot of interest in the research community. Of the sensor-based detection systems, temperature and smoke sensors are a popular choice for this purpose. The sensor-based approach, however, has significant limitations in terms of detection range and detection speed. According to NIST, the average time to raise an accurate alarm using sensor-based detectors is between 60 and 90 seconds. Additionally, sensor-based detectors are susceptible to false alarms. Factors such as dust, steam, or even high humidity can trigger an alarm, leading to unnecessary panic and potential desensitization to real alarms.
With the advancements in machine vision, video surveillance technology has expanded in recent years, speeding up transmission and sensing. Taking advantage of this, researchers at Sertis Vision Lab have developed a fast and accurate fire and smoke detection pipeline by utilizing the capacity of recent deep-learning models to extract and learn pertinent features from images, that aids the pipeline to detect the progression of fire and smoke in video sequences and successfully raise an alarm.
System Design

Integral to Sertis Vision Lab’s fire and smoke detection system is a deep-learning-based detection model, which processes a sequence of video frames and subsequently infers on the given sequence. Being adept at processing continuous video streams, the model generates detection scores for every video frame it infers on. These detection scores, which are reflective of the model’s confidence in identifying the presence of any fire or smoke instances per video frame, are meticulously analyzed by a temporal analysis module, as shown in Fig.1. This dual-step detection strategy ensures that threats are evaluated for their continuity and progression, thus minimizing false alarms and ensuring that genuine threats are acted upon promptly.
Detection Model Development
With the recent advancements in the field of object detection, various deep-learning based detection models have been developed for analyzing images with complex scenes, being able to effectively distinguish the target objects from a cluttered background. Identifying instances of fire and smoke in images is a challenging task as both these classes have a high intra-class variance, assuming different shapes, colors and textures, making the learning process more complicated than for well-defined objects. Additionally, there might be multiple instances of fire or smoke in a single image. Keeping this in mind, Sertis Vision Lab developed their own deep-learning detection models to accurately detect instances of fire and smoke in input images. Fig.2 and Fig.3 illustrate the localizing capability of the detection models in the form of bounding boxes and confidence scores.


Model Performance Criterion
For detection models, precise localization of the predicted bounding boxes is reflective of their ability to detect objects in images. However, to scale the testing of the trained detection models’ performance on videos would require annotating bounding boxes for every frame of each video in the test set. Therefore, researchers at Sertis Vision Lab instead test the detection models’ ability to identify any instance of fire/smoke in an input image rather than accurately trying to localize any or all instances of fire/smoke. This allows testing for the models’ ability to accurately “classify” an input image as fire or smoke or both without requiring rigorous annotation for bounding boxes. This might raise the question as to why not simply train a classification model? The answer lies in the capability of deep-learning based detection models, trained on diverse datasets, to learn extensive robustness to variations in color, shape, size, texture, as well as environmental factors such as lighting and background. This robustness makes them the ideal choice for reliable detection of fire and smoke instances.
Dataset Curation
For the development of the fire/smoke detection models, Sertis Vision Lab curated their own training dataset with an intention to capture the high intra-class variance for both the classes and to incorporate data points from the same domain as CCTV feed on which these models are intended to be deployed. This training dataset is a mixture of images and video frames scraped using the Bing search engine and YouTube, respectively. This resulted in a dataset with 5259 images which were then subsequently annotated with bounding box information.
As per the model performance criterion, the trained models were evaluated based on their ability to detect any instance of fire/smoke in an input image. For this purpose, Sertis Vision Lab curated their own test set, comprising of extracted images from real-world video clips which is reflective of the domain in which the models are intended to be deployed. This test set contains 5000 samples for all three classes: fire, smoke, and no fire/no smoke. The accuracy of the trained fire detection and smoke detection models to identify any instance of fire and smoke in an input image on this test set were at 94.4% and 86.6%, respectively.
Temporal Analysis Module
The objects of interest, in the case of fire and smoke detection, tend to grow and change shape rapidly over time, unlike other detection tasks. A temporal analysis module, therefore, aids in the detection of these dynamic changes whilst distinguishing fire and smoke from other environmental objects. Additionally, such a module aids in reducing false alarms by monitoring the persistence and evolution of potential fire and smoke events, ensuring that sporadic heat or smoke signals are not mistakenly identified as threats. This two-stage approach enhances the accuracy and reliability of the overall detection systems.
As shown in Fig.1, the temporal analysis module contributes to tying in the detection information, in the form of detection scores, from previous frames and aids in making a decision to raise an alarm. The parameter that predominantly controls this decision is the buffer frames (n), which is defined as:
“Given a frame fᵀ, the buffer frames are n consecutive preceding frames, fᵀ, fᵀ⁻¹,…,fᵀ⁻ⁿ⁺¹, the detection scores for which are used for successfully raising a fire/smoke alarm with the use of some temporal analysis.”
Fig.4 provides as overview of the mechanism of the temporal analysis module in raising a fire/smoke alarm.
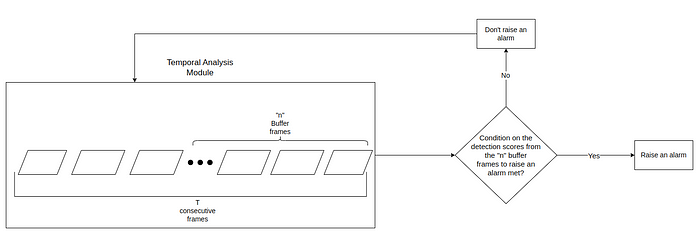
The following two strategies were implemented as a part of the temporal analysis module:
Moving Average Strategy
This strategy is used to compute the detection score for an undetected frame as an average of the last “m” frames with non-zero scores. Through extensive hyper-parameter tuning, a value of m=5 was chosen for all the experiments. The pseudo-code for the temporal analysis module using the moving average strategy is shown in Algorithm 1.
Given,
Buffer frames : n
Optimal confidence threshold : c
Window size : m
List of scores from T consecutive frames (in order of processed frames) : S
Condition : T >= n
zero_imputed_scores_list = S
for i in range(firs_non_zero_idx, len(S)):
if zero_imputed_scores_list[i] == 0:
non_zero_values = []
for j in range(max(0, i-m), i+1):
if S[j] != 0:
non_zero_values.append(S[j])
if non_zero_values:
zero_imputed_scores_list[i] = average(non_zero_values)
filtered_scores = []
for score in zero_imputed_scores_list:
if score >= c:
filtered_scores.append(score)
if len(filtered_scores) == n:
raise alarmAlgorithm 1: Pseudo-code for moving average strategy
Bucket Strategy
Unlike moving average, this strategy involves no post-processing. In this method, given a window in the form of buffer frames, an alarm is raised if a fraction of those consecutive frames have a detection
confidence greater than the optimal threshold. This fraction was chosen to be 0.8 for all their experiments. The pseudo-code for the temporal analysis module using the bucket strategy is shown in Algorithm 2.
Given,
Buffer frames : n
Optimal confidence threshold : c
Required percentage of detected frames : x
List of scores from n consecutive frames (in order of processed frames) : S
Required, minimum number of frames with detection scores >= c : int(x*n)
filtered_scores = []
for score in S:
if score >= c:
filtered_scores.append(score)
if len(filtered_scores) >= int(x*n):
raise alarmAlgorithm 2: Pseudo-code for bucket strategy
Alarm Performance
Metrics
The following metric were chosen to evaluate the alarm raising ability of the proposed system:
- True Alarm Rate (TAR): It is the true positive rate at which true alarms are successfully raised.
- False Alarm Rate (FAR): It is the false positive rate at which an alarm is falsely raised or raised too soon.
- False Non-Alarm Rate (FNAR): It is the false negative rate at which no alarms are raised even when there are instances of fire/smoke.
- Avg. reaction time: The average reaction time for successfully raising a true alarm. As shown in Fig.5, this metric is computed as the difference in the first ground-truth time stamp with fire/smoke instance in a video with the time stamp where the model confidently identifies fire/smoke in a given video feed.

Evaluation
The efficiency of the overall system lies in its ability to successfully raise genuine alarms for fire and smoke disasters captured from CCTV feed. For this purpose, a video test set consisting of 100 videos was curated by scraping YouTube videos. This video test consist of an equal number of positive and negative videos. For positive videos, instances of fire or smoke or both were marked at the frame level. Instead of bounding boxes, the frames, as a whole, were marked True or False for the presence of fire or smoke using the frame-per-second (FPS) of each of the videos, the ground truth time stamps for when fire/smoke start in a video were computed. These ground truth time stamps aided in computing the average reaction time for raising a true fire/smoke alarm. The performance of the proposed pipeline for fire and smoke alarms with different temporal analysis strategies is shown in Table 1. A buffer frames of 52 was found the most optimal for the best performance for both fire and smoke alarms.
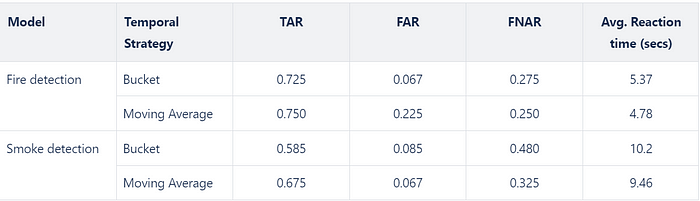

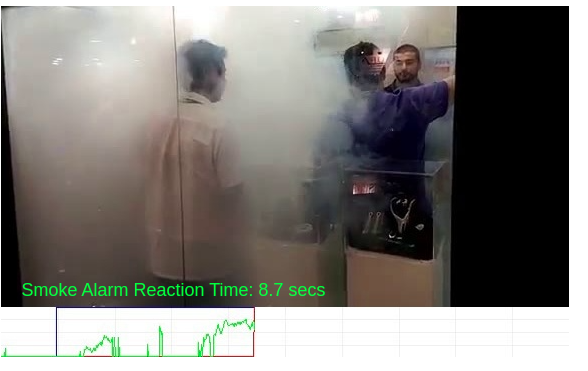
Fig.6 and Fig.7 demonstrate the performance of the proposed system in successfully raising fire and smoke alarms.
Summary
The development of this end-to-end pipeline to successfully raise fast and accurate fire and smoke alarms is another addition to Sertis Vision Lab’s ever-growing arsenal of video surveillance technologies such as customer behavior analysis, automatic number plate recognition, vehicle make & model, and facial recognition to name a few.
Written by: Sertis Vision Lab
Originally published at https://www.sertiscorp.com/sertis-vision-lab
