This blog post is a technical summary on the research paper: Face Detection with Feature Pyramids and Landmarks proposed by Earp et al. [1] in affiliation with Sertis Vision Lab.

Introduction
Object detection, a task in computer vision, refers to localizing objects and classifying them. Accurately solving this task opens the door to a wide range of applications, ranging from autonomous driving to person re-identification. Over recent years, the ever-improving performance of Convolutional Neural Networks (CNNs) has resulted in significant advancements in the object detection methodology. For instance, Region CNNs (RCNNs) [2], commonly used for various detection tasks, perform a computationally expensive greedy selective search algorithm to lower the number of region propositions significantly. An improvement over RCNNs, Faster RCNNs [3] feed pixel-level region proposals into the detection network from the feature maps, slightly reducing the overhead. However, Faster RCNNs, utilize CNN-based Region Proposal Networks (RPNs), removing the greedy selective search used in previous RCNNs, enabling detection in real-time. RPNs use a pyramid of anchors to propose regions more efficiently than pyramids of images [4] or filters. Furthermore, current object detectors rely on multi-scale feature pyramids, which use spatial pyramid pooling [7] to efficiently extract features at different levels from a single image, moving away from the less efficient pyramid of images approach [4]. Multi-scale feature pyramids rely on only a single-scale image and output proportionally sized feature maps at various levels through top-down and lateral connections.
With recent research, object detectors can be broadly classified into two categories — single-stage and two-stage. Single-stage models make independent object classification from multiple feature maps from deep in the network, typically having a latency advantage. A prominent example of the single-stage detector is the RetinaNet [5]. Based on Faster RCNN, RetinaNet when combined with focal loss, has achieved state-of-the-art accuracy on the COCO dataset [6]. However, the feature maps that these detectors leverage have a lower spatial resolution; hence may have already lost some semantic information relating to small objects, generally leading to reduced accuracy.
On the other hand, two-stage detectors construct semantically rich feature maps from different layers in the network and classify regions of interest. As a result, two-stage based architectures can detect small objects with higher precision but with reduced speeds [8]. Finding a balance between accuracy and inference time has been a predominant focus of recent research.
Akin to object detection, face detection refers to the task of accurately providing the bounding box locations for all the detectable faces within an image. However, face detection is challenging due to variations in pose, illumination, resolution, occlusion, and human variance in real-world data. Face recognition technology has become more integrated with our lives, with businesses looking to take advantage of its convenience and robustness. Face detection is the foundation for recognition systems and other face-related research and products, including alignment and attribute classification (e.g., gender, age, face expression). The past decade has seen an increase in research to improve the performance of face detection models with this motivation. An important development in this avenue was the introduction of context modules [10] which are applied between the backbone and the heads, thereby enabling the face detection model to be scale-invariant in unconstrained settings. Feature pyramids, skip connections, and region proposals are some of the few examples of context modules that have been used to improve face detection accuracy. Another essential contribution in this field was the release of the publicly available WIDER FACE dataset [9], which is now widely used to train and benchmark face detection models. Through their paper, Earp et al. [1] contribute to this research area by presenting a series of numerous single-stage face detectors with different sized backbones and a six-layer feature pyramid trained exclusively on the WIDER FACE dataset. They train a model that is comparable to the performance of the state-of-the-art models on the WIDER FACE challenge leaderboard [17].
Proposed methods
Earp et al. [1] propose the following ideas:
- Modification to the pre-existing context modules in face detection literature to study and quantify their influence on the overall performance of the face detection network.
- Use of a multi-task loss function for model training.
Context modules

Fig. 1 demonstrates all the context modules that Earp et al. [1] test in their experiments. The left column shows some of commonly used context modules in face detection research, while the right column shows their slightly modified versions, proposed by Earp et al. [1]. For SSH₂, they modify the context module by dividing the number of channels by four which are then followed by four 3x3 convolutions, all concatenated to get the output. For RSSH₂, they halve the number of channels in the third convolution, which is then followed by a fourth 3x3 convolution and finally all the four outputs are concatenated .For Retina₂, Earp et al. [1] swap the addition and concatenation, and concatenate the last layer with the sum of the first and second layers. For Dense₂, they add a fourth densely connected 3x3 convolution.
Multi-task loss function
Using a multi-task loss function is common practice in detection tasks. For model training, Earp et al. [1] use a loss function which comprises of three components; class, bounding box and landmark loss. The class loss L_cls is given by the log loss over the two classes (face vs back- ground), this is calculated for both positive and negative anchors. The bounding box loss L_box is the smooth-L1 regression loss of the box location, only calculated for positive anchors. Similarly, the landmark loss L_lmk is the regression loss of the landmark locations, also only calculated for the positive anchors. The combination of these three loss functions yields the multi-task loss function as:
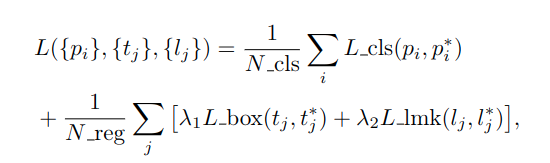
Experiments
Dataset
Earp et al. [1] trained their models on the WIDER FACE dataset [9], consisting of 32,203 images and 393,703 labeled face bounding boxes with variable scale, pose and occlusion. The dataset is organized based on 61 event classes (e.g. parade, riot, and festival). Each event class is randomly sampled, with 40%, 10% and 50% of the images assigned to the training, validation and testing sets. Furthermore, the bounding box proposals in the dataset are split into three difficulty levels: Easy, Medium and Hard with recall rates of 92%, 76%, and 34%, respectively.
For all the experiments, the input image size was maintained to be 640x640.
Models
Earp et al. [1] trained with the following four different backbone network sizes:
- MobileNetV2 [13] [14] with α=0.25 and n=64 filters in the context modules (referred to in paper [1] as MNetₐ₌₀.₂₅).
- MobileNetV2 with α=1.0 and n=128 filters in the context modules (referred to in paper [1] as MNetₐ₌₁.₀).
- ResNet v2 [15] with 101 layers n=256 filters in the context modules (referred to in paper [1] as ResNet101).
- ResNet v2 with 152 layers n=256 filters in the context modules (referred to in paper [1] as ResNet152).
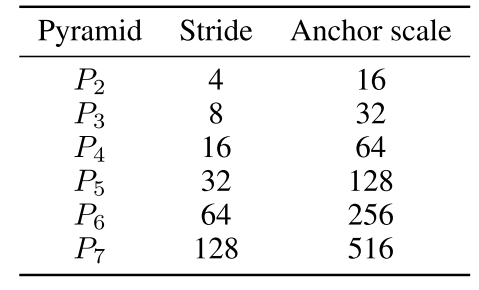
For the feature pyramid setup, Earp et al. [1] used a six-level feature pyramid as shown in Table 1. All anchors were set to an aspect ratio of 1:1. While positive anchors were regarded for detections with intersection-over-union (IoU) greater than 0.5 with ground truth and negative anchors were the ones with IoU less than 0.3. Furthermore, Earp et al. [1] incorporate online hard example mining (OHEM) [16] which has been successfully used in training other RPN based face detectors. Randomly cropping 640x640 regions of the original images was also used during the training procedure.
All models were trained using stochastic gradient descent with momentum 0.9, weight decay of 5x10⁻⁴ and with a batch size of eight on each of six NVIDIA Telsa GPU.
Evaluation Metrics
For the evaluation process, detections were considered true or false based on the area of overlap with the ground truth bounding boxes. For an IoU greater than 0.5 between a positive anchor and the ground truth, it was considered a true positive whereas an IoU value below this is considered a false positive.
For multiple true positive detections of one ground truth, only the detection with the highest IoU was counted as correct and the rest were counted as false positives. The evaluation metric considered was the average precision (AP). For each set (Easy, Medium, Hard) the precisions were drawn from all unique recall values and averaged.
Results
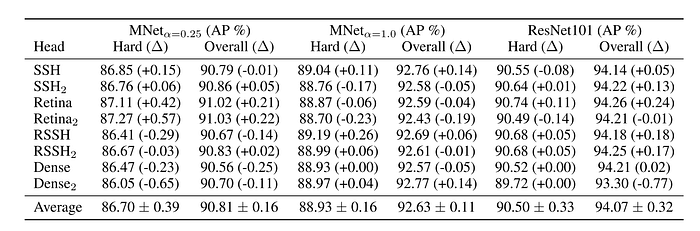
Table 2 shows the performance of all three backbones with different context modules on three sets of the WIDER FACE validation set. For MNetV2ₐ₌₀.₂₅, Retina₂, Retina, and SSH are the three top performers on the ‘Hard’ set, and Retina₂, Retina, and SSH₂ the top overall. For MNetV2ₐ₌₁.₀, Retina₂, Retina, and RSSH₂ are the three top performers on the Hard set, and SSH, Dense₂, and RSSH the top overall. For ResNet101, Retina, RSSH, and RSSH₂ are the three top performers on the ‘Hard’ set, and Retina, RSSH₂, and SSH₂ are the top overall. For the Hard set, Table 2 shows that the top three context performers were Retina, Retina₂ and SSH with average mean divergences of 0.16%, 0.07% and 0.06%, respectively. Over all three sets, the top three context performers were Retina, SSH and RSSH₂ with average mean divergences of 0.08%, 0.02% and 0.02%, respectively.
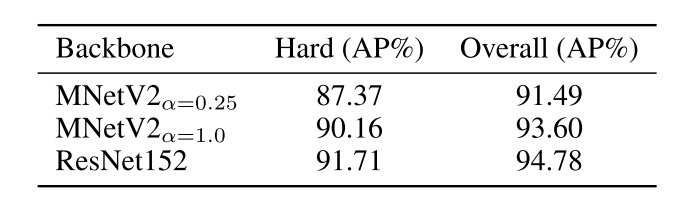
Figure 2 shows the final results on all three of the WIDER FACE validation sets, evaluated in 2019. The ResNet152 model ranked a respectable fourth on both the Medium and Hard sets. Additionally, the MNetV2ₐ₌₀.₂₅ model ranked four to five places higher than EXTD [8] (a similar lightweight detector) on all three sets. Furthermore, the MNetV2ₐ₌₁.₀ model was able to out perform much heavier networks even with ResNet50 backbone.
Conclusion
At the time of writing their paper, Earp et al. [1] show that their largest model, ResNet152, achieves a near state-of-the-art score on the WIDER FACE hard set of ~91.7 percent (Table 3) without making use of any excessive additional layers. Their two smaller networks, MNetV2ₐ₌₀.₂₅ and MNetV2ₐ₌₁.₀ , exceeds state-of-the-art performance on the WIDER FACE Hard set compared to similar network sizes.
Acknowledgements
The development of the face detection research was a collaboration between AI researcher, Ankush Ganguly from Sertis Vision Lab, and Quantitative researchers: Samuel W. F. Earp, Pavit Noinongyao and Justin A. Cairns from QIS Capital.
References:
[3] R. Girshick. Fast R-CNN. arXiv e-prints, art. arXiv:1504.08083, Apr 2015.
Written by Sertis Vision Lab
Originally published at https://www.sertiscorp.com/